Main elements of client-side application components of distributed systems
Distributed systems use client-side elementsfor users to interact with
These client-side elements include
•Views – what users see (mainly GUIs)
•Controllers – contain event handers for the Views
•Client-model – Business logic and data
Views development technologies for the browser-based client-components of web-based applications
•Browser-based clients’ Views comprises two
main elements
•Content – HTML
• Formatting – CSS
•Server/client-side components may generate
the elements of Views
HTML uses different types of elements to
define content
Structural elements
• header, footer, nav, aside, article
Text elements
• Headings – <h1> to <h6>
• Paragraph – <p>
• Line break - <br>
Images
Hyperlinks
Data representational elements (these elements use
nested structures)
• Lists
• Tables
Form elements
• Input
• Radio buttons, check boxes
• Buttons
Cascading Style Sheets
Used to
• Decorate / Format content
•Advantages
• Reduce HTML formatting tags
• Easy modification
• Save lot of work and time
• Faster loading
There are 3 main selectors
•Element selector
• ID selector
•Class selector
Different categories of elements in HTML, proving examples for their use
Structural elements
• header, footer, nav, aside, article
Text elements
• Headings – <h1> to <h6>
• Paragraph – <p>
• Line break - <br>
Images
Hyperlinks
Data representational elements (these elements use
nested structures)
• Lists
• Tables
Form elements
• Input
• Radio buttons, check boxes
• Buttons
Importance of CSS, indicating new features of CSS3
Cascading Style Sheets, commonly known as CSS, is an integral part of the modern web development process. It is a highly effective HTML tool that provides easy control over layout and presentation of website pages by separating content from design.
Although CSS was introduced in 1996, it gained mainstream popularity by the early 2000s when popular browsers started supporting its advanced features. The latest version, CSS3, has been available since 1998 and was last updated in September 2008.
Although CSS was introduced in 1996, it gained mainstream popularity by the early 2000s when popular browsers started supporting its advanced features. The latest version, CSS3, has been available since 1998 and was last updated in September 2008.
Benefits of CSS in Web Development
Improves Website Presentation
The standout advantage of CSS is the added design flexibility and interactivity it brings to web development. Developers have greater control over the layout allowing them to make precise section-wise changes.
As customization through CSS is much easier than plain HTML, web developers are able to create different looks for each page. Complex websites with uniquely presented pages are feasible thanks to CSS.
Makes Updates Easier and Smoother
CSS works by creating rules. These rules are simultaneously applied to multiple elements within the site. Eliminating the repetitive coding style of HTML makes development work faster and less monotonous. Errors are also reduced considerably.
Since the content is completely separated from the design, changes across the website can be implemented all at once. This reduces delivery times and costs of future edits.
Helps Web Pages Load Faster
Improved website loading is an underrated yet important benefit of CSS. Browsers download the CSS rules once and cache them for loading all the pages of a website. It makes browsing the website faster and enhances the overall user experience.
This feature comes in handy in making websites work smoothly at lower internet speeds. Accessibility on low end devices also improves with better loading speeds.
What is CSS 3?
CSS3 is the latest evolution of the Cascading Style Sheets language and aims at extending CSS2.1. It brings a lot of new features and additions, like rounded corners, shadows, gradients, transitions or animations, as well as new layouts like multi-columns, flexible box or grid layouts.
Now let’s have a look at what’s new!
#1. CSS3 Selectors
Selectors are at the heart of CSS. Originally, CSS allowed the matching of elements by type, class, and/or ID. CSS2.1 added pseudo-elements, pseudo-classes, and combinators. With CSS3, we can target almost any element on the page with a wide range of selectors.
CSS2 introduced several attribute selectors. These allow for matching elements based on their attributes. CSS3 expands upon those attribute selectors.Three more attribute selectors were added in CSS3; they allow for substring selection.
1.Matches any element E whose attribute attr starts with the value val. In other words, the val matches the beginning of the attribute value.
E[attr^=val]
eg. a[href^='http://sales.']{color: teal;}
2.Matches any element E whose attribute attr ends in val. In other words, the val matches the end of the attribute value.
E[attr$=val]
eg. a[href$='.jsp']{color: purple;}
3.Matches any element E whose attribute attr matches val anywhere within the attribute. It is similar to E[attr~=val], except the val can be part of a word.
E[attr*=val]
eg. img[src*='artwork']{
border-color: #C3B087 #FFF #FFF #C3B087;
}
Pseudo-classes
It’s likely that you’re already familiar with some of the user interaction pseudo-classes,namely :link, :visited, :hover, :active, and :focus.
A few more pseudo-class selectors were added in CSS3. One is the :root selector, which allows designers to point to the root element of a document. In HTML, it would be <html>. Since :root is generic, it allows a designer to select the root element of an XML document without necessarily knowing it’s name. To permit scrollbars when needed in a document, this rule would work.
:root{overflow:auto;}
As a complement to the :first-child selector, the :last-child was added. With it one can select the last element named of a parent element. For a site with articles contained in <div class=’article’></div> tags, where each has a last paragraph with some information that needs to be uniformly stylized, this rule would change the font for last paragraph of each article.
div.article > p:last-child{font-style: italic;}
A new user interaction pseudo-class selector was added, the :target selector. To draw the user’s attention to a span of text when the user clicks on a same-page link, a rule like the first line below would work nicely; the link would look like the second line, the highlighted span like the third.
span.notice:target{font-size: 2em; font-style: bold;}
<a href='#section2'>Section 2</a>
<p id='section2'>...</p>
A functional notation for selecting specified elements that fail a test has been created. The negation pseudo-class selector, :not can be coupled with almost any other selector that has been implemented. For example to put a border around images that don’t have a border specified, use a rule like this.
img:not([border]){border: 1;}
#2. CSS3 Colors
CSS3 brings with it support for some new ways of describing colours . Prior to CSS3, we almost always declared colours using the hexadecimal format (#FFF, or #FFFFFF for white). It was also possible to declare colours using the rgb() notation, providing either integers (0–255) or percentages.
The color keyword list has been extended in the CSS3 color module to include 147 additional keyword colors (that are generally well supported), CSS3 also provides us with a number of other options: HSL, HSLA, and RGBA. The most notable change with these new color types is the ability to declare semitransparent colors.
- RGBA :
RGBA works just like RGB, except that it adds a fourth value: alpha, the opacity level or alpha transparency level. The first three values still represent red, green, and blue. For the alpha value, 1 means fully opaque, 0 is fully transparent, and 0.5 is 50% opaque. You can use any number between 0 and 1 inclusively.
2. HSL and HSLA
HSL stands for hue, saturation, and lightness. Unlike RGB, where you need to manipulate the saturation or brightness of a color by changing all three color values in concert, with HSL you can tweak either just the saturation or the lightness while keeping the same base hue. The syntax for HSL comprises an integer value for hue, and percentage values for saturation and lightness.
The hsl( ) declaration accepts three values:
— The hue in degrees from 0 to 359. Some examples are: 0 = red, 60 = yellow, 120= green, 180 = cyan, 240 = blue, and 300 = magenta.
— The saturation as a percentage with 100% being the norm. Saturation of 100% will be the full hue, and saturation of 0 will give you a shade of gray — essentially causing the hue value to be ignored.
— A percentage for lightness with 50% being the norm. A lightness of 100% will be white, 50% will be the actual hue, and 0% will be black.
The a in hsla( ) here also functions the same way as in rgba( )
3.Opacity
In addition to specifying transparency with HSLA and RGBA colors (and soon, eight-digit hexadecimal values), CSS3 provides us with the opacity property. opacity sets the opaqueness of the element on which it’s declared, similar to alpha.
Let’s look at an example:
div.halfopaque {
background-color: rgb(0, 0, 0);
opacity: 0.5;
color: #000000;
}
div.halfalpha {
background-color: rgba(0, 0, 0, 0.5);
color: #000000;
}
Though the usage of both alpha and opacity notations seem similar, when you look at it, there is a key difference in their function.
While opacity sets the opacity value for an element and all of its children, a semitransparent RGBA or HSLA color has no impact on the element’s other CSS properties or descendants.
#3. Rounded Corners: border-radius
The border-radius property lets you create rounded corners without the need for images or additional markup. To add rounded corners to our box, we simply add
border-radius: 25px;
The border-radius property is actually a shorthand. For our “a” element, the corners are all the same size and symmetrical. If we had wanted different-sized corners, we could declare up to four unique values
border-radius: 5px 10px 15px 20px;
#4. Drop Shadows
CSS3 provides the ability to add drop shadows to elements using the box-shadow property. This property lets you specify the color, height, width, blur, and offset of one or multiple inner and/or outer drop shadows on your elements.
box-shadow: 2px 5px 0 0 rgba(72,72,72,1);
#5. Text Shadow
text-shadow adds shadows to individual characters in text nodes. Prior to CSS 3, this would be done by either using an image or duplicating a text element and then positioning it.
text-shadow: topOffset leftOffset blurRadius color;
#6. Linear Gradients
W3C added the syntax for generating linear gradients with CSS3.
Syntax: background: linear-gradient(direction, color-stop1, color-stop2, ...);
e.g. #grad {
background: linear-gradient(to right, red , yellow);
}

You can even specify direction in degrees e.g. 60deg instead of to right in the above example .
#7. Radial Gradients
Radial gradients are circular or elliptical gradients. Rather than proceeding along a straight axis, colors blend out from a starting point in all directions.
Syntax : background: radial-gradient(shape size at position, start-color, ..., last-color);
e.g. #grad {
background: radial-gradient(red, yellow, green);
}//Default
#grad {
background: radial-gradient(circle, red, yellow, green);
}//Circle
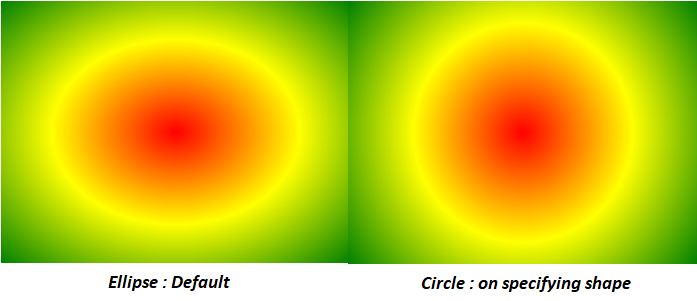
#8.Multiple Background Images
In CSS3, there’s no need to include an element for every background image; it provides us with the ability to add more than one background image to any element, even to pseudo-elements.
background-image: url(firstImage.jpg), url(secondImage.gif), url(thirdImage.png);
These are the implemented CSS3 features that are new.
3 main types of CSS selectors
The element Selector
The element selector selects elements based on the element name.
You can select all <p> elements on a page like this (in this case, all <p> elements will be center-aligned, with a red text color):
Example
p {
text-align: center;
color: red;}
The id Selector
The id selector uses the id attribute of an HTML element to select a specific element.
The id of an element should be unique within a page, so the id selector is used to select one unique element!
To select an element with a specific id, write a hash (#) character, followed by the id of the element.
The style rule below will be applied to the HTML element with id="para1":
Example
#para1 {
text-align: center;
color: red;}
Note: An id name cannot start with a number!
The class Selector
The class selector selects elements with a specific class attribute.
To select elements with a specific class, write a period (.) character, followed by the name of the class.
In the example below, all HTML elements with class="center" will be red and center-aligned:
Example
.center {
text-align: center;
color: red;}
You can also specify that only specific HTML elements should be affected by a class.
In the example below, only <p> elements with class="center" will be center-aligned:
Example
p.center {
text-align: center;
color: red;}
HTML elements can also refer to more than one class.
In the example below, the <p> element will be styled according to class="center" and to class="large":
Example
<p class="center large">This paragraph refers to two classes.</p>
Note: A class name cannot start with a number!Advanced CSS selectors, explaining the specificity

Use for CSS media queries in responsive web development
By targeting the browser width, we can style content to look appropriate for a wide desktop browser, a medium-sized tablet browser, or a small phone browser. Adjusting the layout of a web page based on the width of the browser is called "responsive design." Responsive design is made possible by CSS media queries.
In this how to, you'll learn how to use media queries in responsive design.
- Start with an HTML page and a set of default CSS styles. These styles will be used by the browser no matter what width the browser is.
- After the
footerstyles, write the following media query. This will apply the CSS within it whenever the browser width is less than or equal to 700px.@media screen and (max-width: 700px) { } - Between the curly braces of the media query, you can override the default styles to change the layout of the page for smaller browsers, like this:
@media screen and (max-width: 700px) { article { float: none; width: 98%; padding: 1%; background-color: #ffaaaa; } aside { float: none; width: 98%; padding: 1%; background-color: #ffaaff; } footer { display: none; } } - Open the HTML page in a browser. This code renders the following, if your browser window is greater than 700px wide:

- Drag the right edge of your web browser to make it narrower. When the width of the browser gets to 700px or less, the layout will change to the following:

<!DOCTYPE HTML>
<html>
<head>
<meta charset="UTF-8">
<title>Media Queries Example</title>
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<style>
body {
background-color: #ccc;
}
#main {
background-color: #fff;
width: 80%;
margin: 0 auto;
padding: 2em;
}
article {
float: right;
width: 64.6666666%;
padding: 1%;
background-color: #ffaaaa;
}
aside {
float: left;
width: 31.3333333%;
padding: 1%;
background-color: #ffaaff;
}
footer {
clear: both;
}
</style>
</head>
<body>
<div id="main">
<header>
<h1>Media Queries</h1>
</header>
<article>
<h2>Main Content</h2>
<p>This is main content - it shows on right on desktops, on bottom on phones</p>
<p>This is main content - it shows on right on desktops, on bottom on phones</p>
<p>This is main content - it shows on right on desktops, on bottom on phones</p>
<p>This is main content - it shows on right on desktops, on bottom on phones</p>
<p>This is main content - it shows on right on desktops, on bottom on phones</p>
</article>
<aside>
<h2>Sidebar Content</h2>
<p>This is sidebar content - it shows on left on desktops, on bottom on phones</p>
<p>This is sidebar content - it shows on left on desktops, on bottom on phones</p>
<p>This is sidebar content - it shows on left on desktops, on bottom on phones</p>
</aside>
<footer>
<p>This is the footer - it shows only on desktops</p>
</footer>
</div>
</body>
</html>
Pros and cons of 3 ways of using CSS (inline,internal, external)
Option 1 – Internal CSS
Internal CSS code is put in the
<head> section of a particular page. The classes and IDs can be used to refer to the CSS code, but they are only active on that particular page. CSS styles embedded this way are downloaded each time the page loads so it may increase loading speed. However, there are some cases when using internal stylesheet is useful. One example would be sending someone a page template – as everything is in one page, it is a lot easier to see a preview. Internal CSS is put in between <style></style> tags. An example of internal stylesheet:<head>
<style type="text/css">
p {color:white; font-size: 10px;}
.center {display: block; margin: 0 auto;}
#button-go, #button-back {border: solid 1px black;}
</style>
</head>
Advantages of Internal CSS:
- Only one page is affected by stylesheet.
- Classes and IDs can be used by internal stylesheet.
- There is no need to upload multiple files. HTML and CSS can be in the same file.
Disadvantages of Internal CSS:
- Increased page loading time.
- It affects only one page – not useful if you want to use the same CSS on multiple documents.
How to add Internal CSS to HTML page
- Open your HTML page with any text editor. If the page is already uploaded to your hosting account, you can use a text editor provided by your hosting. If you have an HTML document on your computer, you can use any text editor to edit it and then re-upload the file to your hosting account using FTP client.
- Locate
<head>opening tag and add the following code just after it:<style type="text/css"> - Now jump to a new line and add CSS rules, for example:
body { background-color: blue; } h1 { color: red; padding: 60px; } - Once you are done adding CSS rules, add the closing style tag:
</style>
At the end, HTML document with internal stylesheet should look like this:
<!DOCTYPE html>
<html>
<head>
<style>
body {
background-color: blue;
}
h1 {
color: red;
padding: 60px;
}
</style>
</head>
<body>
<h1>Hostinger Tutorials</h1>
<p>This is our paragraph.</p>
</body>
</html>Option 2 – External CSS
Probably the most convenient way to add CSS to your website, is to link it to an external .css file. That way any changes you made to an external CSS file will be reflected on your website globally. A reference to an external CSS file is put in the
<head> section of the page:<head>
<link rel="stylesheet" type="text/css" href="style.css" />
</head>
while the style.css contains all the style rules. For example:
.xleftcol {
float: left;
width: 33%;
background:#809900;
}
.xmiddlecol {
float: left;
width: 34%;
background:#eff2df;
}
Advantages of External CSS:
- Smaller size of HTML pages and cleaner structure.
- Faster loading speed.
- Same .css file can be used on multiple pages.
Disadvantages of External CSS:
- Until external CSS is loaded, the page may not be rendered correctly.
Option 3 – Inline CSS
Inline CSS is used for a specific HTML tag.
<style> attribute is used to style a particular HTML tag. Using CSS this way is not recommended, as each HTML tag needs to be styled individually. Managing your website may become too hard if you only use inline CSS. However, it can be useful in some situations. For example, in cases when you don’t have an access to CSS files or need to apply style for a single element only. An example of HTML page with inline CSS would look like this:<!DOCTYPE html>
<html>
<body style="background-color:black;">
<h1 style="color:white;padding:30px;">Hostinger Tutorials</h1>
<p style="color:white;">Something usefull here.</p>
</body>
</html>
Advantages of Inline CSS:
- Useful if you want to test and preview changes.
- Useful for quick-fixes.
- Lower HTTP requests.
Disadvantages of Inline CSS:
- Inline CSS must be applied to every element.
New features in JS version 6
There are three major categories of features:
- Better syntax for features that already exist (e.g. via libraries). For example:
- New functionality in the standard library. For example:
- New methods for strings and Arrays
- Promises
- Maps, Sets
- Completely new features. For example:
30.2 New number and Math features
30.2.1 New integer literals
You can now specify integers in binary and octal notation:
30.2.2 New Number properties
The global object
Number gained a few new properties:Number.EPSILONfor comparing floating point numbers with a tolerance for rounding errors.Number.isInteger(num)checks whethernumis an integer (a number without a decimal fraction):> Number.isInteger(1.05) false > Number.isInteger(1) true > Number.isInteger(-3.1) false > Number.isInteger(-3) true- A method and constants for determining whether a JavaScript integer is safe(within the signed 53 bit range in which there is no loss of precision):
Number.isSafeInteger(number)Number.MIN_SAFE_INTEGERNumber.MAX_SAFE_INTEGER
Number.isNaN(num)checks whethernumis the valueNaN. In contrast to the global functionisNaN(), it doesn’t coerce its argument to a number and is therefore safer for non-numbers:> isNaN('???') true > Number.isNaN('???') false- Three additional methods of
Numberare mostly equivalent to the global functions with the same names:Number.isFinite,Number.parseFloat,Number.parseInt.
30.2.3 New Math methods
The global object
Math has new methods for numerical, trigonometric and bitwise operations. Let’s look at four examples.Math.sign() returns the sign of a number:Math.trunc() removes the decimal fraction of a number:Math.log10() computes the logarithm to base 10:Math.hypot() Computes the square root of the sum of the squares of its arguments (Pythagoras’ theorem):30.3 New string features
New string methods:
ES6 has a new kind of string literal, the template literal:
// String interpolation via template literals (in backticks)
const first = 'Jane';
const last = 'Doe';
console.log(`Hello ${first} ${last}!`);
// Hello Jane Doe!
// Template literals also let you create strings with multiple lines
const multiLine = `
This is
a string
with multiple
lines`;
30.4 Symbols
Symbols are a new primitive type in ECMAScript 6. They are created via a factory function:
const mySymbol = Symbol('mySymbol');
Every time you call the factory function, a new and unique symbol is created. The optional parameter is a descriptive string that is shown when printing the symbol (it has no other purpose):
30.4.1 Use case 1: unique property keys
Symbols are mainly used as unique property keys – a symbol never clashes with any other property key (symbol or string). For example, you can make an object iterable (usable via the
for-of loop and other language mechanisms), by using the symbol stored in Symbol.iterator as the key of a method (more information on iterables is given in the chapter on iteration):const iterableObject = {
[Symbol.iterator]() { // (A)
···
}
}
for (const x of iterableObject) {
console.log(x);
}
// Output:
// hello
// world
In line A, a symbol is used as the key of the method. This unique marker makes the object iterable and enables us to use the
for-of loop.30.4.2 Use case 2: constants representing concepts
In ECMAScript 5, you may have used strings to represent concepts such as colors. In ES6, you can use symbols and be sure that they are always unique:
const COLOR_RED = Symbol('Red');
const COLOR_ORANGE = Symbol('Orange');
const COLOR_YELLOW = Symbol('Yellow');
const COLOR_GREEN = Symbol('Green');
const COLOR_BLUE = Symbol('Blue');
const COLOR_VIOLET = Symbol('Violet');
function getComplement(color) {
switch (color) {
case COLOR_RED:
return COLOR_GREEN;
case COLOR_ORANGE:
return COLOR_BLUE;
case COLOR_YELLOW:
return COLOR_VIOLET;
case COLOR_GREEN:
return COLOR_RED;
case COLOR_BLUE:
return COLOR_ORANGE;
case COLOR_VIOLET:
return COLOR_YELLOW;
default:
throw new Exception('Unknown color: '+color);
}
}
Every time you call
Symbol('Red'), a new symbol is created. Therefore, COLOR_RED can never be mistaken for another value. That would be different if it were the string 'Red'.30.4.3 Pitfall: you can’t coerce symbols to strings
Coercing (implicitly converting) symbols to strings throws exceptions:
const sym = Symbol('desc');
const str1 = '' + sym; // TypeError
const str2 = `${sym}`; // TypeError
The only solution is to convert explicitly:
const str2 = String(sym); // 'Symbol(desc)'
const str3 = sym.toString(); // 'Symbol(desc)'
Forbidding coercion prevents some errors, but also makes working with symbols more complicated.
30.4.4 Which operations related to property keys are aware of symbols?
The following operations are aware of symbols as property keys:
Reflect.ownKeys()- Property access via
[] Object.assign()
The following operations ignore symbols as property keys:
Object.keys()Object.getOwnPropertyNames()for-inloop
30.5 Template literals
ES6 has two new kinds of literals: template literals and tagged template literals. These two literals have similar names and look similar, but they are quite different. It is therefore important to distinguish:
- Template literals (code): multi-line string literals that support interpolation
- Tagged template literals (code): function calls
- Web templates (data): HTML with blanks to be filled in
Template literals are string literals that can stretch across multiple lines and include interpolated expressions (inserted via
${···}):const firstName = 'Jane';
console.log(`Hello ${firstName}!
How are you
today?`);
// Output:
// Hello Jane!
// How are you
// today?
Tagged template literals (short: tagged templates) are created by mentioning a function before a template literal:
Tagged templates are function calls. In the previous example, the method
String.rawis called to produce the result of the tagged template.30.6 Variables and scoping
ES6 provides two new ways of declaring variables:
let and const, which mostly replace the ES5 way of declaring variables, var.
30.6.1 let
let works similarly to var, but the variable it declares is block-scoped, it only exists within the current block. var is function-scoped.
In the following code, you can see that the
let-declared variable tmp only exists inside the block that starts in line A:function order(x, y) {
if (x > y) { // (A)
let tmp = x;
x = y;
y = tmp;
}
console.log(tmp===x); // ReferenceError: tmp is not defined
return [x, y];
}
30.6.2 const
const works like let, but the variable you declare must be immediately initialized, with a value that can’t be changed afterwards.const foo;
// SyntaxError: missing = in const declaration
const bar = 123;
bar = 456;
// TypeError: `bar` is read-only
Since
for-of creates one binding (storage space for a variable) per loop iteration, it is OK to const-declare the loop variable:for (const x of ['a', 'b']) {
console.log(x);
}
// Output:
// a
// b
30.6.3 Ways of declaring variables
The following table gives an overview of six ways in which variables can be declared in ES6 (inspired by a table by kangax):
| Hoisting | Scope | Creates global properties | |
|---|---|---|---|
var | Declaration | Function | Yes |
let | Temporal dead zone | Block | No |
const | Temporal dead zone | Block | No |
function | Complete | Block | Yes |
class | No | Block | No |
import | Complete | Module-global | No |
30.7 Destructuring
Destructuring is a convenient way of extracting multiple values from data stored in (possibly nested) objects and Arrays. It can be used in locations that receive data (such as the left-hand side of an assignment). How to extract the values is specified via patterns (read on for examples).
30.7.1 Object destructuring
Destructuring objects:
const obj = { first: 'Jane', last: 'Doe' };
const {first: f, last: l} = obj;
// f = 'Jane'; l = 'Doe'
// {prop} is short for {prop: prop}
const {first, last} = obj;
// first = 'Jane'; last = 'Doe'
Destructuring helps with processing return values:
const obj = { foo: 123 };
const {writable, configurable} =
Object.getOwnPropertyDescriptor(obj, 'foo');
console.log(writable, configurable); // true true
30.7.2 Array destructuring
Array destructuring (works for all iterable values):
const iterable = ['a', 'b'];
const [x, y] = iterable;
// x = 'a'; y = 'b'
Destructuring helps with processing return values:
const [all, year, month, day] =
/^(\d\d\d\d)-(\d\d)-(\d\d)$/
.exec('2999-12-31');
30.7.3 Where can destructuring be used?
Destructuring can be used in the following locations (I’m showing Array patterns to demonstrate; object patterns work just as well):
// Variable declarations:
const [x] = ['a'];
let [x] = ['a'];
var [x] = ['a'];
// Assignments:
[x] = ['a'];
// Parameter definitions:
function f([x]) { ··· }
f(['a']);
You can also destructure in a
for-of loop:const arr = ['a', 'b'];
for (const [index, element] of arr.entries()) {
console.log(index, element);
}
// Output:
// 0 a
// 1 b
30.8 Parameter handling
Parameter handling has been significantly upgraded in ECMAScript 6. It now supports parameter default values, rest parameters (varargs) and destructuring.
Additionally, the spread operator helps with function/method/constructor calls and Array literals.
30.8.1 Default parameter values
A default parameter value is specified for a parameter via an equals sign (
=). If a caller doesn’t provide a value for the parameter, the default value is used. In the following example, the default parameter value of y is 0:function func(x, y=0) {
return [x, y];
}
func(1, 2); // [1, 2]
func(1); // [1, 0]
func(); // [undefined, 0]
30.8.2 Rest parameters
If you prefix a parameter name with the rest operator (
...), that parameter receives all remaining parameters via an Array:function format(pattern, ...params) {
return {pattern, params};
}
format(1, 2, 3);
// { pattern: 1, params: [ 2, 3 ] }
format();
// { pattern: undefined, params: [] }
30.8.3 Named parameters via destructuring
You can simulate named parameters if you destructure with an object pattern in the parameter list:
function selectEntries({ start=0, end=-1, step=1 } = {}) { // (A)
// The object pattern is an abbreviation of:
// { start: start=0, end: end=-1, step: step=1 }
// Use the variables `start`, `end` and `step` here
···
}
selectEntries({ start: 10, end: 30, step: 2 });
selectEntries({ step: 3 });
selectEntries({});
selectEntries();
The
= {} in line A enables you to call selectEntries() without paramters.
30.8.4 Spread operator (...)
In function and constructor calls, the spread operator turns iterable values into arguments:
> Math.max(-1, 5, 11, 3)
11
> Math.max(...[-1, 5, 11, 3])
11
> Math.max(-1, ...[-5, 11], 3)
11
In Array literals, the spread operator turns iterable values into Array elements:
> [1, ...[2,3], 4]
[1, 2, 3, 4]
30.9 Callable entities in ECMAScript 6
In ES5, a single construct, the (traditional) function, played three roles:
- Real (non-method) function
- Method
- Constructor
In ES6, there is more specialization. The three duties are now handled as follows. As far as function definitions and class definitions are concerned, a definition is either a declaration or an expression.
- Real (non-method) function:
- Arrow functions (only have an expression form)
- Traditional functions (created via function definitions)
- Generator functions (created via generator function definitions)
- Method:
- Methods (created by method definitions in object literals and class definitions)
- Generator methods (created by generator method definitions in object literals and class definitions)
- Constructor:
- Classes (created via class definitions)
Especially for callbacks, arrow functions are handy, because they don’t shadow the
this of the surrounding scope.
For longer callbacks and stand-alone functions, traditional functions can be OK. Some APIs use
this as an implicit parameter. In that case, you have no choice but to use traditional functions.
Note that I distinguish:
- The entities: e.g. traditional functions
- The syntax that creates the entities: e.g. function definitions
Even though their behaviors differ (as explained later), all of these entities are functions. For example:
30.10 Arrow functions
There are two benefits to arrow functions.
First, they are less verbose than traditional function expressions:
const arr = [1, 2, 3];
const squares = arr.map(x => x * x);
// Traditional function expression:
const squares = arr.map(function (x) { return x * x });
Second, their
this is picked up from surroundings (lexical). Therefore, you don’t need bind() or that = this, anymore.function UiComponent() {
const button = document.getElementById('myButton');
button.addEventListener('click', () => {
console.log('CLICK');
this.handleClick(); // lexical `this`
});
}
The following variables are all lexical inside arrow functions:
argumentssuperthisnew.target
30.11 New OOP features besides classes
30.11.1 New object literal features
Method definitions:
const obj = {
myMethod(x, y) {
···
}
};
Property value shorthands:
const first = 'Jane';
const last = 'Doe';
const obj = { first, last };
// Same as:
const obj = { first: first, last: last };
Computed property keys:
const propKey = 'foo';
const obj = {
[propKey]: true,
['b'+'ar']: 123
};
This new syntax can also be used for method definitions:
const obj = {
['h'+'ello']() {
return 'hi';
}
};
console.log(obj.hello()); // hi
The main use case for computed property keys is to make it easy to use symbols as property keys.
30.11.2 New methods in Object
The most important new method of
Object is assign(). Traditionally, this functionality was called extend() in the JavaScript world. In contrast to how this classic operation works, Object.assign() only considers own (non-inherited) properties.const obj = { foo: 123 };
Object.assign(obj, { bar: true });
console.log(JSON.stringify(obj));
// {"foo":123,"bar":true}
30.12 Classes
A class and a subclass:
class Point {
constructor(x, y) {
this.x = x;
this.y = y;
}
toString() {
return `(${this.x}, ${this.y})`;
}
}
class ColorPoint extends Point {
constructor(x, y, color) {
super(x, y);
this.color = color;
}
toString() {
return super.toString() + ' in ' + this.color;
}
}
Using the classes:
Under the hood, ES6 classes are not something that is radically new: They mainly provide more convenient syntax to create old-school constructor functions. You can see that if you use
typeof:30.13 Modules
JavaScript has had modules for a long time. However, they were implemented via libraries, not built into the language. ES6 is the first time that JavaScript has built-in modules.
ES6 modules are stored in files. There is exactly one module per file and one file per module. You have two ways of exporting things from a module. These two ways can be mixed, but it is usually better to use them separately.
30.13.1 Multiple named exports
There can be multiple named exports:
//------ lib.js ------
export const sqrt = Math.sqrt;
export function square(x) {
return x * x;
}
export function diag(x, y) {
return sqrt(square(x) + square(y));
}
//------ main.js ------
import { square, diag } from 'lib';
console.log(square(11)); // 121
console.log(diag(4, 3)); // 5
You can also import the complete module:
//------ main.js ------
import * as lib from 'lib';
console.log(lib.square(11)); // 121
console.log(lib.diag(4, 3)); // 5
30.13.2 Single default export
There can be a single default export. For example, a function:
//------ myFunc.js ------
export default function () { ··· } // no semicolon!
//------ main1.js ------
import myFunc from 'myFunc';
myFunc();
Or a class:
//------ MyClass.js ------
export default class { ··· } // no semicolon!
//------ main2.js ------
import MyClass from 'MyClass';
const inst = new MyClass();
Note that there is no semicolon at the end if you default-export a function or a class (which are anonymous declarations).
30.13.3 Browsers: scripts versus modules
| Scripts | Modules | |
|---|---|---|
| HTML element | <script> | <script type="module"> |
| Default mode | non-strict | strict |
| Top-level variables are | global | local to module |
Value of this at top level | window | undefined |
| Executed | synchronously | asynchronously |
Declarative imports (import statement) | no | yes |
| Programmatic imports (Promise-based API) | yes | yes |
| File extension | .js | .js |
30.14 The for-of loop
for-of is a new loop in ES6 that replaces both for-in and forEach() and supports the new iteration protocol.
Use it to loop over iterable objects (Arrays, strings, Maps, Sets, etc.; see Chap. “Iterables and iterators”):
const iterable = ['a', 'b'];
for (const x of iterable) {
console.log(x);
}
// Output:
// a
// b
break and continue work inside for-of loops:for (const x of ['a', '', 'b']) {
if (x.length === 0) break;
console.log(x);
}
// Output:
// a
Access both elements and their indices while looping over an Array (the square brackets before
of mean that we are using destructuring):const arr = ['a', 'b'];
for (const [index, element] of arr.entries()) {
console.log(`${index}. ${element}`);
}
// Output:
// 0. a
// 1. b
Looping over the [key, value] entries in a Map (the square brackets before
of mean that we are using destructuring):const map = new Map([
[false, 'no'],
[true, 'yes'],
]);
for (const [key, value] of map) {
console.log(`${key} => ${value}`);
}
// Output:
// false => no
// true => yes
30.15 New Array features
New static
Array methods:Array.from(arrayLike, mapFunc?, thisArg?)Array.of(...items)
New
Array.prototype methods:- Iterating:
Array.prototype.entries()Array.prototype.keys()Array.prototype.values()
- Searching for elements:
Array.prototype.find(predicate, thisArg?)Array.prototype.findIndex(predicate, thisArg?)
Array.prototype.copyWithin(target, start, end=this.length)Array.prototype.fill(value, start=0, end=this.length)
30.16 Maps and Sets
Among others, the following four data structures are new in ECMAScript 6:
Map, WeakMap, Set and WeakSet.30.16.1 Maps
The keys of a Map can be arbitrary values:
You can use an Array (or any iterable) with [key, value] pairs to set up the initial data in the Map:
const map = new Map([
[ 1, 'one' ],
[ 2, 'two' ],
[ 3, 'three' ], // trailing comma is ignored
]);
30.16.2 Sets
A Set is a collection of unique elements:
As you can see, you can initialize a Set with elements if you hand the constructor an iterable (
arr in the example) over those elements.30.16.3 WeakMaps
A WeakMap is a Map that doesn’t prevent its keys from being garbage-collected. That means that you can associate data with objects without having to worry about memory leaks. For example:
//----- Manage listeners
const _objToListeners = new WeakMap();
function addListener(obj, listener) {
if (! _objToListeners.has(obj)) {
_objToListeners.set(obj, new Set());
}
_objToListeners.get(obj).add(listener);
}
function triggerListeners(obj) {
const listeners = _objToListeners.get(obj);
if (listeners) {
for (const listener of listeners) {
listener();
}
}
}
//----- Example: attach listeners to an object
const obj = {};
addListener(obj, () => console.log('hello'));
addListener(obj, () => console.log('world'));
//----- Example: trigger listeners
triggerListeners(obj);
// Output:
// hello
// world
30.17 Typed Arrays
Typed Arrays are an ECMAScript 6 API for handling binary data.
Code example:
const typedArray = new Uint8Array([0,1,2]);
console.log(typedArray.length); // 3
typedArray[0] = 5;
const normalArray = [...typedArray]; // [5,1,2]
// The elements are stored in typedArray.buffer.
// Get a different view on the same data:
const dataView = new DataView(typedArray.buffer);
console.log(dataView.getUint8(0)); // 5
Instances of
ArrayBuffer store the binary data to be processed. Two kinds of viewsare used to access the data:- Typed Arrays (
Uint8Array,Int16Array,Float32Array, etc.) interpret the ArrayBuffer as an indexed sequence of elements of a single type. - Instances of
DataViewlet you access data as elements of several types (Uint8,Int16,Float32, etc.), at any byte offset inside an ArrayBuffer.
The following browser APIs support Typed Arrays (details are mentioned in a dedicated section):
- File API
- XMLHttpRequest
- Fetch API
- Canvas
- WebSockets
- And more
30.18 Iterables and iterators
ES6 introduces a new mechanism for traversing data: iteration. Two concepts are central to iteration:
- An iterable is a data structure that wants to make its elements accessible to the public. It does so by implementing a method whose key is
Symbol.iterator. That method is a factory for iterators. - An iterator is a pointer for traversing the elements of a data structure (think cursors in databases).
Expressed as interfaces in TypeScript notation, these roles look like this:
interface Iterable {
[Symbol.iterator]() : Iterator;
}
interface Iterator {
next() : IteratorResult;
}
interface IteratorResult {
value: any;
done: boolean;
}
30.18.1 Iterable values
The following values are iterable:
- Arrays
- Strings
- Maps
- Sets
- DOM data structures (work in progress)
Plain objects are not iterable (why is explained in a dedicated section).
30.18.2 Constructs supporting iteration
Language constructs that access data via iteration:
- Destructuring via an Array pattern:
const[a,b]=newSet(['a','b','c']); for-ofloop:for(constxof['a','b','c']){console.log(x);}Array.from():constarr=Array.from(newSet(['a','b','c']));- Spread operator (
...):constarr=[...newSet(['a','b','c'])]; - Constructors of Maps and Sets:
constmap=newMap([[false,'no'],[true,'yes']]);constset=newSet(['a','b','c']); Promise.all(),Promise.race():Promise.all(iterableOverPromises).then(···);Promise.race(iterableOverPromises).then(···);yield*:yield*anIterable;
30.19 Generators
30.19.1 What are generators?
You can think of generators as processes (pieces of code) that you can pause and resume:
function* genFunc() {
// (A)
console.log('First');
yield;
console.log('Second');
}
Note the new syntax:
function* is a new “keyword” for generator functions (there are also generator methods). yield is an operator with which a generator can pause itself. Additionally, generators can also receive input and send output via yield.
When you call a generator function
genFunc(), you get a generator object genObj that you can use to control the process:const genObj = genFunc();
The process is initially paused in line A.
genObj.next() resumes execution, a yieldinside genFunc() pauses execution:genObj.next();
// Output: First
genObj.next();
// output: Second
30.19.2 Kinds of generators
There are four kinds of generators:
- Generator function declarations:
function*genFunc(){···}constgenObj=genFunc(); - Generator function expressions:
constgenFunc=function*(){···};constgenObj=genFunc(); - Generator method definitions in object literals:
constobj={*generatorMethod(){···}};constgenObj=obj.generatorMethod(); - Generator method definitions in class definitions (class declarations or class expressions):
classMyClass{*generatorMethod(){···}}constmyInst=newMyClass();constgenObj=myInst.generatorMethod();
30.19.3 Use case: implementing iterables
The objects returned by generators are iterable; each
yield contributes to the sequence of iterated values. Therefore, you can use generators to implement iterables, which can be consumed by various ES6 language mechanisms: for-ofloop, spread operator (...), etc.
The following function returns an iterable over the properties of an object, one [key, value] pair per property:
function* objectEntries(obj) {
const propKeys = Reflect.ownKeys(obj);
for (const propKey of propKeys) {
// `yield` returns a value and then pauses
// the generator. Later, execution continues
// where it was previously paused.
yield [propKey, obj[propKey]];
}
}
objectEntries() is used like this:const jane = { first: 'Jane', last: 'Doe' };
for (const [key,value] of objectEntries(jane)) {
console.log(`${key}: ${value}`);
}
// Output:
// first: Jane
// last: Doe
How exactly
objectEntries() works is explained in a dedicated section. Implementing the same functionality without generators is much more work.30.19.4 Use case: simpler asynchronous code
You can use generators to tremendously simplify working with Promises. Let’s look at a Promise-based function
fetchJson() and how it can be improved via generators.function fetchJson(url) {
return fetch(url)
.then(request => request.text())
.then(text => {
return JSON.parse(text);
})
.catch(error => {
console.log(`ERROR: ${error.stack}`);
});
}
With the library co and a generator, this asynchronous code looks synchronous:
const fetchJson = co.wrap(function* (url) {
try {
let request = yield fetch(url);
let text = yield request.text();
return JSON.parse(text);
}
catch (error) {
console.log(`ERROR: ${error.stack}`);
}
});
ECMAScript 2017 will have async functions which are internally based on generators. With them, the code looks like this:
async function fetchJson(url) {
try {
let request = await fetch(url);
let text = await request.text();
return JSON.parse(text);
}
catch (error) {
console.log(`ERROR: ${error.stack}`);
}
}
All versions can be invoked like this:
fetchJson('http://example.com/some_file.json')
.then(obj => console.log(obj));
30.19.5 Use case: receiving asynchronous data
Generators can receive input from
next() via yield. That means that you can wake up a generator whenever new data arrives asynchronously and to the generator it feels like it receives the data synchronously.30.20 New regular expression features
The following regular expression features are new in ECMAScript 6:
- The new flag
/y(sticky) anchors each match of a regular expression to the end of the previous match. - The new flag
/u(unicode) handles surrogate pairs (such as\uD83D\uDE80) as code points and lets you use Unicode code point escapes (such as\u{1F680}) in regular expressions. - The new data property
flagsgives you access to the flags of a regular expression, just likesourcealready gives you access to the pattern in ES5:> /abc/ig.source // ES5 'abc' > /abc/ig.flags // ES6 'gi' - You can use the constructor
RegExp()to make a copy of a regular expression:> new RegExp(/abc/ig).flags 'gi' > new RegExp(/abc/ig, 'i').flags // change flags 'i'
30.21 Promises for asynchronous programming
Promises are an alternative to callbacks for delivering the results of an asynchronous computation. They require more effort from implementors of asynchronous functions, but provide several benefits for users of those functions.
The following function returns a result asynchronously, via a Promise:
function asyncFunc() {
return new Promise(
function (resolve, reject) {
···
resolve(result);
···
reject(error);
});
}
You call
asyncFunc() as follows:asyncFunc()
.then(result => { ··· })
.catch(error => { ··· });
30.21.1 Chaining then() calls
then() always returns a Promise, which enables you to chain method calls:asyncFunc1()
.then(result1 => {
// Use result1
return asyncFunction2(); // (A)
})
.then(result2 => { // (B)
// Use result2
})
.catch(error => {
// Handle errors of asyncFunc1() and asyncFunc2()
});
How the Promise P returned by
then() is settled depends on what its callback does:- If it returns a Promise (as in line A), the settlement of that Promise is forwarded to P. That’s why the callback from line B can pick up the settlement of
asyncFunction2’s Promise. - If it returns a different value, that value is used to settle P.
- If throws an exception then P is rejected with that exception.
Furthermore, note how
catch() handles the errors of two asynchronous function calls (asyncFunction1() and asyncFunction2()). That is, uncaught errors are passed on until there is an error handler.30.21.2 Executing asynchronous functions in parallel
If you chain asynchronous function calls via
then(), they are executed sequentially, one at a time:asyncFunc1()
.then(() => asyncFunc2());
If you don’t do that and call all of them immediately, they are basically executed in parallel (a fork in Unix process terminology):
asyncFunc1();
asyncFunc2();
Promise.all() enables you to be notified once all results are in (a join in Unix process terminology). Its input is an Array of Promises, its output a single Promise that is fulfilled with an Array of the results.Promise.all([
asyncFunc1(),
asyncFunc2(),
])
.then(([result1, result2]) => {
···
})
.catch(err => {
// Receives first rejection among the Promises
···
});
30.21.3 Glossary: Promises
The Promise API is about delivering results asynchronously. A Promise object (short: Promise) is a stand-in for the result, which is delivered via that object.
States:
- A Promise is always in one of three mutually exclusive states:
- Before the result is ready, the Promise is pending.
- If a result is available, the Promise is fulfilled.
- If an error happened, the Promise is rejected.
- A Promise is settled if “things are done” (if it is either fulfilled or rejected).
- A Promise is settled exactly once and then remains unchanged.
Reacting to state changes:
- Promise reactions are callbacks that you register with the Promise method
then(), to be notified of a fulfillment or a rejection. - A thenable is an object that has a Promise-style
then()method. Whenever the API is only interested in being notified of settlements, it only demands thenables (e.g. the values returned fromthen()andcatch(); or the values handed toPromise.all()andPromise.race()).
Changing states: There are two operations for changing the state of a Promise. After you have invoked either one of them once, further invocations have no effect.
- Rejecting a Promise means that the Promise becomes rejected.
- Resolving a Promise has different effects, depending on what value you are resolving with:
- Resolving with a normal (non-thenable) value fulfills the Promise.
- Resolving a Promise P with a thenable T means that P can’t be resolved anymore and will now follow T’s state, including its fulfillment or rejection value. The appropriate P reactions will get called once T settles (or are called immediately if T is already settled).
30.22 Metaprogramming with proxies
Proxies enable you to intercept and customize operations performed on objects (such as getting properties). They are a metaprogramming feature.
In the following example,
proxy is the object whose operations we are intercepting and handler is the object that handles the interceptions. In this case, we are only intercepting a single operation, get (getting properties).const target = {};
const handler = {
get(target, propKey, receiver) {
console.log('get ' + propKey);
return 123;
}
};
const proxy = new Proxy(target, handler);
When we get the property
proxy.foo, the handler intercepts that operation:
Consult the reference for the complete API for a list of operations that can be intercepted.



No comments:
Post a Comment