Role of data in information systems
All information systems require the input of data in order to perform organizational activities. Data, as described by Stair and Reynolds (2006), is made up of raw facts such as employee information, wages, and hours worked, barcode numbers, tracking numbers or sale numbers. The scope of data collected depends on what information needs to be extrapolated for maximum efficiency. Kumar and Palvia (2001) state that: “ Data plays a vital role in organizations, and in recent years companies have recognized the significance of corporate data as an organizational asset” (¶ 4). Raw data on it’s own however, has no representational value (Stair and Reynolds, 2006). Data is collected in order to create information and knowledge about particular subjects that interest any given organization in order for that organization to make better management decisions.
Data
Data are raw facts that can be processed and converted to meaningful information.
Database
A database is an organized collection of data, generally stored and accessed electronically from a computer system. Where databases are more complex they are often developed using formal design and modeling techniques.
Database server
A database server is a server which houses a database application that provides database services to other computer programs or to computers, as defined by the client–server model.
Database Management System
A database management system (DBMS) is system software for creating and managing databases. The DBMS provides users and programmers with a systematic way to create, retrieve, update and manage data.







File System vs. Database
Pros of the File System
- Performance can be better than when you do it in a database. To justify this, if you store large files in DB, then it may slow down the performance because a simple query to retrieve the list of files or filename will also load the file data if you used
Select *in your query. In a files ystem, accessing a file is quite simple and light weight. - Saving the files and downloading them in the file system is much simpler than it is in a database since a simple "Save As" function will help you out. Downloading can be done by addressing a URL with the location of the saved file.
- Migrating the data is an easy process. You can just copy and paste the folder to your desired destination while ensuring that write permissions are provided to your destination.
- It's cost effective in most cases to expand your web server rather than pay for certain databases.
- It's easy to migrate it to cloud storage i.e. Amazon S3, CDNs, etc. in the future.
Cons of the File System
- Loosely packed. There are no ACID (Atomicity, Consistency, Isolation, Durability) operations in relational mapping, which means there is no guarantee. Consider a scenario in which your files are deleted from the location manually or by some hacking dudes. You might not know whether the file exists or not. Painful, right?
- Low security. Since your files can be saved in a folder where you should have provided write permissions, it is prone to safety issues and invites trouble, like hacking. It's best to avoid saving in the file system if you cannot afford to compromise in terms of security.
Pros of Database
- ACID consistency, which includes a rollback of an update that is complicated when files are stored outside the database.
- Files will be in sync with the database and cannot be orphaned, which gives you the upper hand in tracking transactions.
- Backups automatically include file binaries.
- It's more secure than saving in a file system.
Cons of Database
- You may have to convert the files to blob in order to store them in the database.
- Database backups will be more hefty and heavy.
- Memory is ineffective. Often, RDBMSs are RAM-driven, so all data has to go to RAM first. Yeah, that’s right. Have you ever thought about what happens when an RDBMS has to find and sort data? RDBMS tracks each data page — even the lowest amount of data read and written — and it has to track if it’s in-memory or if it’s on-disk, if it’s indexed or if it's sorted physically etc.
Different arrangements of data
Big Data includes huge valume, high velocity, and extensible variaty of data. These are 3 types: Structured data, Semi-structured data, and Unstructured data.
- Structured data –
Structured data is a data whose elements are addressable for effective analysis. It has been organised into a formatted repository that is typically a database. It concern all data which can be stored in database SQL in table with rows and columns. They have relational key and can easily mapped into pre-designed fields. Today, those data are most processed in development and simplest way to manage information. Example: Relational data. - semi-structured data –
Semi-structured data is information that does not reside in a rational database but that have some organizational properties that make it easier to analyze. With some process, you can store them in the relation database (it could be very hard for some kind of semi-structured data), but Semi-structured exist to ease space. Example: XML data. - Unstructured data –
Unstructured data is a data that is which is not organised in a pre-defined manner or does not have a pre-defined data model, thus it is not a good fit for a mainstream relational database. So for Unstructured data, there are alternative platforms for storing and managing, it is increasingly prevalent in IT systems and is used by organizations in a variety of business intelligence and analytics applications. Example: Word, PDF, Text, Media logs.
Different types of databases
There are several types of database management systems. Here is a list of seven common database management systems:
- Hierarchical databases
- Network databases
- Relational databases
- Object-oriented databases
- Graph databases
- ER model databases
- Document databases
Hierarchical Databases
In a hierarchical database management systems (hierarchical DBMSs) model, data is stored in a parent-children relationship nodes. In a hierarchical database, besides actual data, records also contain information about their groups of parent/child relationships.
In a hierarchical database model, data is organized into a tree like structure. The data is stored in form of collection of fields where each field contains only one value. The records are linked to each other via links into a parent-children relationship. In a hierarchical database model, each child record has only one parent. A parent can have multiple children.
To retrieve a field’s data, we need to traversed through each tree until the record is found.
The hierarchical database system structure was developed by IBM in early 1960s. While hierarchical structure is simple, it is inflexible due to the parent-child one-to-many relationship. Hierarchical databases are widely used to build high performance and availability applications usually in banking and telecommunications industries.
The IBM Information Management System (IMS) and Windows Registry are two popular examples of hierarchical databases.
Advantage
Hierarchical database can be accessed and updated rapidly because in this model structure is like as a tree and the relationships between records are defined in advance. This feature is a two-edged.
Disadvantage This type of database structure is that each child in the tree may have only one parent, and relationships or linkages between children are not permitted, even if they make sense from a logical standpoint. Hierarchical databases are so in their design. it can adding a new field or record requires that the entire database be redefined.
Network Databases
Network database management systems (Network DBMSs) use a network structure to create relationship between entities. Network databases are mainly used on a large digital computers. Network databases are hierarchical databases but unlike hierarchical databases where one node can have one parent only, a network node can have relationship with multiple entities. A network database looks more like a cobweb or interconnected network of records.
In network databases, children are called members and parents are called occupier. The difference between each child or member can have more than one parent.
The approval of the network data model is similar to a hierarchical data model. Data in a network database is organized in many-to-many relationships.
The network database structure was invented by Charles Bachman. Some of the popular network databases are Integrated Data Store (IDS), IDMS (Integrated Database Management System), Raima Database Manager, TurboIMAGE, and Univac DMS-1100.
Relational Databases
In relational database management systems (RDBMS), the relationship between data is relational and data is stored in tabular form of columns and rows. Each column if a table represents an attribute and each row in a table represents a record. Each field in a table represents a data value.
Structured Query Language (SQL) is a the language used to query a RDBMS including inserting, updating, deleting, and searching records.
Relational databases work on each table has a key field that uniquely indicates each row, and that these key fields can be used to connect one table of data to another.
Relational databases are the most popular and widely used databases. Some of the popular DDBMS are Oracle, SQL Server, MySQL, SQLite, and IBM DB2.
The relational database has two major reasons
- Relational databases can be used with little or no training.
- Database entries can be modified without specify the entire body.
Properties of Relational Tables
In the relational database we have to follow some properties which are given below.
- It's Values are Atomic
- In Each Row is alone.
- Column Values are of the Same thing.
- Columns is undistinguished.
- Sequence of Rows is Insignificant.
- Each Column has a common Name.
RDBMs are the most popular databases. Learn here Most Popular Database In the World.
Object-Oriented Model
In this Model we have to discuss the functionality of the object oriented Programming. It takes more than storage of programming language objects. Object DBMS's increase the semantics of the C++ and Java.I t provides full-featured database programming capability, while containing native language compatibility. It adds the database functionality to object programming languages. This approach is the analogical of the application and database development into a constant data model and language environment. Applications require less code, use more natural data modeling, and code bases are easier to maintain. Object developers can write complete database applications with a decent amount of additional effort.
The object-oriented database derivation is the integrity of object-oriented programming language systems and consistent systems. The power of the object-oriented databases comes from the cyclical treatment of both consistent data, as found in databases, and transient data, as found in executing programs.
Object-oriented databases use small, recyclable separated of software called objects. The objects themselves are stored in the object-oriented database. Each object contains of two elements:
- Piece of data (e.g., sound, video, text, or graphics).
- Instructions, or software programs called methods, for what to do with the data.
Object-oriented database management systems (OODBMs) were created in early 1980s. Some OODBMs were designed to work with OOP languages such as Delphi, Ruby, C++, Java, and Python. Some popular OODBMs are TORNADO, Gemstone, ObjectStore, GBase, VBase, InterSystems Cache, Versant Object Database, ODABA, ZODB, Poet. JADE, and Informix.
Disadvantage of Object-oriented databases
- Object-oriented databases have these disadvantages.
- Object-oriented database are more expensive to develop.
- In the Most organizations are unwilling to abandon and convert from those databases.
Benefits of Object-oriented databases
The benefits to object-oriented databases are compelling. The ability to mix and match reusable objects provides incredible multimedia capability.
Graph Databases
Graph Databases are NoSQL databases and use a graph structure for sematic queries. The data is stored in form of nodes, edges, and properties. In a graph database, a Node represent an entity or instance such as customer, person, or a car. A node is equivalent to a record in a relational database system. An Edge in a graph database represents a relationship that connects nodes. Properties are additional information added to the nodes.
The Neo4j, Azure Cosmos DB, SAP HANA, Sparksee, Oracle Spatial and Graph, OrientDB, ArrangoDB, and MarkLogic are some of the popular graph databases. Graph database structure is also supported by some RDBMs including Oracle and SQL Server 2017 and later versions.
ER Model Databases
An ER model is typically implemented as a database. In a simple relational database implementation, each row of a table represents one instance of an entity type, and each field in a table represents an attribute type. In a relational database a relationship between entities is implemented by storing the primary key of one entity as a pointer or "foreign key" in the table of another entity.
Entity-relationship model was developed by Peter Chen 1976.
Document Databases
Document databases (Document DB) are also NoSQL database that store data in form of documents. Each document represents the data, its relationship between other data elements, and attributes of data. Document database store data in a key value form.
Document DB has become popular recently due to their document storage and NoSQL properties. NoSQL data storage provide faster mechanism to store and search documents.
Popular NoSQL databases are Hadoop/Hbase, Cassandra, Hypertable, MapR, Hortonworks, Cloudera, Amazon SimpleDB, Apache Flink, IBM Informix, Elastic, MongoDB, and Azure DocumentDB.
Big data vs Warehouse
| BASIS FOR COMPARISON | DATA WAREHOUSE | BIG DATA |
| Meaning | Data Warehouse is mainly an architecture, not a technology. It extracting data from varieties SQL based data source (mainly relational database) and help for generating analytic reports. In terms of definition, data repository, which using for any analytic reports, has been generated from one process, which is nothing but the data warehouse. | Big Data is mainly a technology, which stands on volume, velocity, and variety of the data. Volumes define the amount of data coming from different sources, velocity refers to the speed of data processing, and varieties refer to the number of types of data (mainly support all type of data format). |
| Preferences | If an organization wants to know some informed decision (like what is going on in their corporation, next year planning based on current year performance data etc), they prefer to choose data warehousing, as for this kind of report they need reliable or believable data from the sources. | If organization need to compare with a lot of big data, which contain valuable information and help them to take a better decision (like how to lead more revenue, more profitability, more customers etc), they obviously preferred Big Data approach. |
| Accepted Data Source | Accepted one or more homogeneous (all sites use the same DBMS product) or heterogeneous (sites may run different DBMS product) data sources. | Accepted any kind of sources, including business transactions, social media, and information from sensor or machine specific data. It can come from DBMS product or not. |
| Accepted type of formats | Handles mainly structural data (specifically relational data). | Accepted all types of formats. Structure data, relational data, and unstructured data including text documents, email, video, audio, stock ticker data and financial transaction. |
| Subject-Oriented | Data warehouse is subject oriented because it actually provides information on the specific subject (like a product, customers, suppliers, sales, revenue etc) not on organization ongoing operation. It does not focus on ongoing operation, it mainly focuses on analysis or displaying data which help on decision making. | Big Data is also subject-oriented, the main difference is a source of data, as big data can accept and process data from all the sources including social media, sensor or machine specific data. It also main on provide exact analysis on data specifically on subject oriented. |
| Time-Variant | The data collected in a data warehouse is actually identified by a particular time period. As it mainly holds historical data for an analytical report. | Big Data have a lot of approach to identified already loaded data, a time period is one of the approaches on it. As Big data mainly processing flat files, so archive with date and time will be the best approach to identify loaded data. But it have the option to work with streaming data, so it not always holding historical data. |
| Non-volatile | Previous data never erase when new data added to it. This is one of the major features of a data warehouse. As it totally different from an operational database, so any changes on an operational database will not directly impact to a data warehouse. | For Big data, again previous data never erase when new data added to it. It stored as a file which represents a table. But here sometime in case of streaming directly use Hive or Spark as operation environment. |
| Distributed File System | Processing of huge data in Data Warehousing is really time-consuming and sometimes it took an entire day for complete the process. | This is one of the big utility of Big Data. HDFS (Hadoop Distributed File System) mainly defined to load huge data in distributed systems by using map reduce program. |
How the application components communicate with files and databases
Application components are logically coupled solely by the event relationships they share. An event type is dynamically created whenever a publisher publishes a new event type or a consumer subscribes to a new event type not already in the ENS database. This aspect is totally runtime-configured.
SQL statements, Prepared statements, and Callable statements
The Statement is used for executing a static SQL statement.
The PreparedStatement is used for executing a precompiled SQL statement.
The CallableStatement is an interface which is used to execute SQL stored procedures, cursors, and Functions.
So PreparedStatement is faster than Statement. It becomes more visible when we reuse the PreparedStatement or use it’s batch processing methods for executing multiple queries. and it helps us in preventing SQL injection attacks because it automatically escapes the special characters.
Just as a Connection object creates the Statement and PreparedStatement objects, it also creates the CallableStatement object.The CallableStatement interface is a subinterface of PreparedStatement it adds a level of abstraction, so the execution of stored procedure or
functions doesn't need a specific DBMS.
functions doesn't need a specific DBMS.
Need for ORM
Object-relational-mapping is the idea of being able to write queries like the one above, as well as much more complicated ones, using the object-oriented paradigm of your preferred programming language.
Long story short, we are trying to interact with our database using our language of choice instead of SQL.
Here’s where the Object-relational-mapper comes in. When most people say “ORM” they are referring to a library that implements this technique. For example, the above query would now look something like this:
var orm = require('generic-orm-libarry');
var user = orm("users").where({ email: 'test@test.com' });
As you can see, we are using an imaginary ORM library to execute the exact same query, except we can write it in JavaScript (or whatever language you’re using). We can use the same languages we know and love, and also abstract away some of the complexity of interfacing with a database.
As with any technique, there are tradeoffs that should be considered when using an ORM.
What are some pros of using an ORM? 👍
- You get to write in the language you are already using anyway. If we’re being honest, we probably aren’t the greatest at writing SQL statements. SQL is a ridiculously powerful language, but most of us don’t write in it often. We do, however, tend to be much more fluent in one language or another and being able to leverage that fluency is awesome!
- It abstracts away the database system so that switching from MySQL to PostgreSQL, or whatever flavor you prefer, is easy-peasy.
- Depending on the ORM you get a lot of advanced features out of the box, such as support for transactions, connection pooling, migrations, seeds, streams, and all sorts of other goodies.
- Many of the queries you write will perform better than if you wrote them yourself.
What are some cons of using an ORM? 👎
- If you are a master at SQL, you can probably get more performant queries by writing them yourself.
- There is overhead involved in learning how to use any given ORM.
- The initial configuration of an ORM can be a headache.
- As a developer, it is important to understand what is happening under the hood. Since ORMs can serve as a crutch to avoid understanding databases and SQL, it can make you a weaker developer in that portion of the stack.
What are some popular ORMs?
Wikipedia has a great list of ORMs that exist for just about any language. That list is missing JavaScript, which is my language of choice, so I will throw my hat in the ring for Knex.js.
They’re not paying me to say that, I’ve simply enjoyed working with their software and I don’t have any experience with other JavaScript ORMs. This article might provide more insightful feedback for JavaScript specifically.
POJO vs Java Beans
POJO classes
POJO stands for Plain Old Java Object. It is an ordinary Java object, not bound by any special restriction other than those forced by the Java Language Specification and not requiring any class path. POJOs are used for increasing the readability and re-usability of a program. POJOs have gained most acceptance because they are easy to write and understand. They were introduced in EJB 3.0 by Sun microsystems.
A POJO should not:
- Extend prespecified classes, Ex: public class GFG extends javax.servlet.http.HttpServlet { … } is not a POJO class.
- Implement prespecified interfaces, Ex: public class Bar implements javax.ejb.EntityBean { … } is not a POJO class.
- Contain prespecified annotations, Ex: @javax.persistence.Entity public class Baz { … } is not a POJO class.
POJOs basically defines an entity. Like in you program, if you want a Employee class then you can create a POJO as follows:
The above example is a well defined example of POJO class. As you can see, there is no restriction on access-modifier of fields. They can be private, default, protected or public. It is also not necessary to include any constructor in it.
POJO is an object which encapsulates Business Logic. Following image shows a working example of POJO class. Controllers get interact with your business logic which in turn interact with POJO to access the database. In this example a database entity is represented by POJO. This POJO has the same members as database entity.
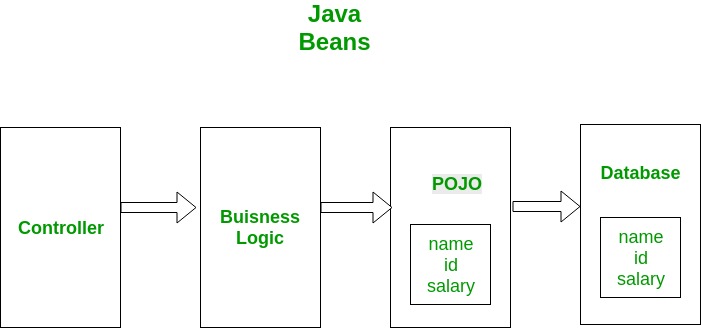
Java Beans
Beans are special type of Pojos. There are some restrictions on POJO to be a bean.
- All JavaBeans are POJOs but not all POJOs are JavaBeans.
- Serializable i.e. they should implement Serializable interface. Still some POJOs who don’t implement Serializable interface are called POJOs beacause Serializable is a marker interface and therefore not of much burden.
- Fields should be private. This is to provide the complete control on fields.
- Fields should have getters or setters or both.
- A no-arg constructor should be there in a bean.
- Fields are accessed only by constructor or getter setters.
Getters and Setters have some special names depending on field name. For example, if field name is someProperty then its getter preferably will be:
public void getSomeProperty()
{
return someProperty;
}
and setter will be
public void setSomePRoperty(someProperty)
{
this.someProperty=someProperty;
}
Visibility of getters and setters in generally public. Getters and setters provide the complete restriction on fields. e.g. consider below property,
Integer age;
If you set visibility of age to public, then any object can use this. Suppose you want that age can’t be 0. In that case you can’t have control. Any object can set it 0. But by using setter method, you have control. You can have a condition in your setter method. Similarly, for getter method if you want that if your age is 0 then it should return null, you can achieve this by using getter method as in following example:
Output:-
After setting to 0: null After setting to valid value: 5
POJO vs Java Bean
| POJO | JAVA BEAN |
|---|---|
| It doesn’t have special restrictions other than those forced by Java language. | It is a special POJO which have some restrictions. |
| It doesn’t provide much control on members. | It provides complete control on members. |
| It can implement Serializable interface. | It should implement serializable interface. |
| Fields can be accessed by their names. | Fields are accessed only by getters and setters. |
| Fields can have any visiblity. | Fields have only private visiblity. |
| There can be a no-arg constructor. | It must have a no-arg constructor. |
| It is used when you don’t want to give restriction on your members and give user complete access of your entity | It is used when you want to provide user your entity but only some part of your entity. |
Conclusion
POJO classes and Beans both are used to define java objects to increase their readability and reusability. POJOs don’t have other restrictions while beans are special POJOs with some restrictions.
This article is contributed by Vishal Garg. If you like GeeksforGeeks and would like to contribute, you can also write an article using contribute.geeksforgeeks.org or mail your article to contribute@geeksforgeeks.org. See your article appearing on the GeeksforGeeks main page and help other Geeks.
Please write comments if you find anything incorrect, or you want to share more information about the topic discussed above.
Java Persistence API (JPA)
Java Persistence API is a Java Specification and Standard for Object Relational Mapping (ORM). In Object Relational Mapping we create Java Objects which represents the database entities. ORM also provides an EntityManager which provides methods to create, delete, update and find the objects from database. We don’t need to write low level queries, we just need to use entity manager and access the entities through java objects.
Initially, JPA was an internal part of Enterprise Java Beans specifications. Where the business entity beans used to be mapped with relational databases. In the EJB 3.0 the specifications regarding data access layer were moved out as an independent specification which was named as Java Persistence API.
ORM tools available for different development platforms (Java, PHP, and .Net)
Java[edit]
- ActiveJDBC, Java implementation of Active record pattern, inspired by Ruby on Rails
- ActiveJPA, open-source Java ORM JPA-like implementation of Active record pattern
- Apache Cayenne, open-source for Java
- Apache Gora, open-source software framework provides an in-memory data model and persistence for big data focused on NoSQL and SQL stores
- Athena Framework, open-source Java ORM, native support for multitenancy SaaS and remoting to Adobe Flex
- Carbonado, open-source framework, backed by Berkeley DB or JDBC
- DataNucleus, open-source JDO and JPA implementation (formerly known as JPOX)
- Ebean, open-source ORM framework
- EclipseLink, Eclipse persistence platform
- Enterprise JavaBeans (EJB)
- Enterprise Objects Framework, Mac OS X/Java, part of Apple WebObjects
- Fast Java Object Relation Mapping (Fjorm)
- Hibernate, open-source ORM framework, widely used
- Java Data Objects (JDO)
- Java Object Oriented Querying (jOOQ)
- Kodo, commercial implementation of both Java Data Objects and Java Persistence API
- Kundera, open-source framework, JPA compliant, polyglot object-datastore mapping library for NoSQL datastores
- MyBatis, free open-source, formerly named iBATIS
- QuickDB ORM, open-source ORM framework
- Speedment, an open source stream ORM
- TopLink by Oracle
- Torque, an object-relational mapper for Java
.NET[edit]
- Base One Foundation Component Library, free or commercial
- DatabaseObjects .NET, open source
- DataObjects.NET, commercial
- Dapper, open source
- ECO, commercial but free use for up to 12 classes
- Entity Framework, included in .NET Framework 3.5 SP1 and above
- iBATIS, free open source, maintained by ASF but now inactive.
- LINQ to SQL, included in .NET Framework 3.5
- Neo, open source but now inactive.
- NHibernate, open source
- nHydrate, open source
- Quick Objects, free or commercial
- RepoDb, free, open source
- SubSonic, open source but now inactive
- XPO, free, commercial technical support
PHP[edit]
- CakePHP, ORM and framework for PHP 5, open source (scalars, arrays, objects); based on database introspection, no class extending
- CodeIgniter, framework that includes an ActiveRecord implementation
- Doctrine, open source ORM for PHP 5.2.3, 5.3.X. Free software (MIT)
- FuelPHP, ORM and framework for PHP 5.3, released under the MIT license. Based on the ActiveRecord pattern.
- Laravel, framework that contains an ORM called "Eloquent" an ActiveRecord implementation.
- Maghead, a database framework designed for PHP7 includes ORM, Sharding, DBAL, SQL Builder tools etc. free software, released under MIT license.
- Propel, ORM and query-toolkit for PHP 5, inspired by Apache Torque, free software, MIT
- Qcodo, ORM and framework for PHP 5, open source
- QCubed, A community driven fork of Qcodo
- Rocks, open source ORM for PHP 5.1 plus, free for non-commercial use, GPL
- Redbean, ORM layer for PHP 5, creates and maintains tables on the fly, open source, BSD
- Skipper, visualization tool and a code/schema generator for PHP ORM frameworks, commercial
- Torpor, open source ORM for PHP 5.1 plus, free software, MIT, database and OS agnostic
- Yii, ORM and framework for PHP 5, released under the BSD license. Based on the ActiveRecord pattern.
- Zend Framework, framework that includes a table data gateway and row data gateway implementations.
Need for NoSQL
Organizations are increasingly adopting NoSQL databases in response to the complexity and limitations of traditional, legacy relational databases. NoSQL databases are more scalable, can help you achieve better performance, and offers a more cost-effective way of developing, implementing and sharing software.
Key benefits of NoSQL include:
- Efficient, scale-out architecture instead of monolithic architecture
- The ability to handle high volumes of structured, semi-structured, and unstructured data
- Being better aligned with object-oriented programming
- Working well with today's software development methodologies that involve agile sprints and frequent code pushes
Types of NoSQL databases-
There are 4 basic types of NoSQL databases:
- Key-Value Store – It has a Big Hash Table of keys & values {Example- Riak, Amazon S3 (Dynamo)}
- Document-based Store- It stores documents made up of tagged elements. {Example- CouchDB}
- Column-based Store- Each storage block contains data from only one column, {Example- HBase, Cassandra}
- Graph-based-A network database that uses edges and nodes to represent and store data. {Example- Neo4J}
Hadoop
Hadoop is an open source distributed processing framework that manages data processing and storage for big data applications running in clustered systems. It is at the center of a growing ecosystem of big data technologies that are primarily used to support advanced analytics initiatives, including predictive analytics, data mining and machine learning applications. Hadoop can handle various forms of structured and unstructured data, giving users more flexibility for collecting, processing and analyzing data than relational databases and data warehouses provide.
Hadoop core concepts
• Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data
• Hadoop YARN: A framework for job scheduling and cluster resource management.
• Hadoop Map Reduce: A YARN-based system for parallel processing of large data sets
Concept of IR
•Data in the storages should be fetched, converted into information, and produced for proper use.
• Information is retrieved via search queries
• Keyword search
• Full-text search
•The output can be
• Text
• Multimedia
•The information retrieval process should be
• Fast/performance
•Scalable
•Efficient
•Reliable/Correct

Major implementations
• Elasticsearch (https://www.elastic.co/products/elasticsearch)
• Solr (http://lucene.apache.org/solr/)
•Mainly used in search engines and recommendation
systems, with ranking
• Additionally may use
• Natural language processing
• AI/Machine learning
• Ranking



No comments:
Post a Comment