Distributed systems vs distributed computing
Distributed systems are systems, whose components are distributed among multiple devices and using a network for the communication between these components.
Distributed computing is a model in which components of a software system are shared among multiple computers to improve efficiency and performance.
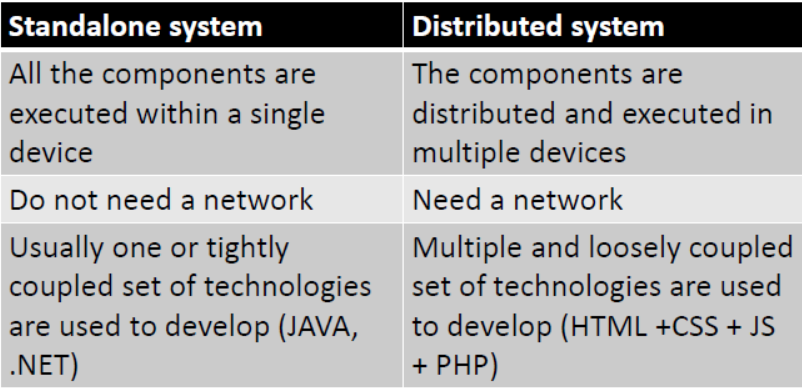
Standalone systems vs distributed systems
Elements of distributed systems
There are three basic components of a distributed system. These are concurrency of components, lack of a global clock, and independent failure of components.
Different types of services, which can be gained from distributed systems
- Mail service - SMTP, POP3, IMAP
- File transferring and sharing - FTP
- Remote logging - telnet
- Games and multimedia - RTP, SIP, H.26x
- Web - HTTP
Examples for both browser-based and non-browser-based clients of distributed systems
Browser based- Web applications
Non-browser-based - Client-Server applications
An application that runs on the client side and accesses the remote server for information is called a client/server application whereas an application that runs entirely on a web browser is known as a web application.
Examples for web applications :
- Yahoo mail
- Gmail
- WebOffice
- Google Apps
- Microsoft Office Live
- WebEx
Examples for client server applications:
- Turnstiles in the subway station
- ATM machines
- POS terminals that accept payments by the credit or debit cards in the store
Characteristics of different types of Web-based systems
Web sites
- Accessible to all users
A user-friendly website should also be accessible to everyone including blind, disabled or the elderly. These users typically use screen-readers to access the Internet. The 508 website accessibility guidelines highlights simple web design techniques that can be applied to make sure your website can be accessed easily on-screen readers, making your website available to a larger audience.
- Well planned Information Architecture
How information is organised and presented on your website is vital for good usability. However, it is often neglected. It has become even more important today as websites offer a wide range of information and resources to attract their target market. Plan your website sections and categories carefully and present information in a way that it is easy for users to find. Always think from the perspective of your users. This is particularly important if you offer a lot of content on your company's website.
- Well formatted content that is easy to scan
The average Internet user skims through the content on a web page instead of reading each and every word from top to down. Users tend to scan through key parts of the page quickly to determine if it is relevant to their needs.
It is important to format your content with this in mind. Correct use of headings, sub-headings, paragraphs, bullets or lists help to break up text, making it easy for readers to scan.
- Fast load time
Nothing is more annoying for website visitors than a website that takes long to load. In fact, slow speed is one of the main reasons why visitors leave a website. Making sure your website loads within 4 to 6 seconds is important for good usability. It also affects your search engine ranking.
- Browser consistency
Browser compatibility can be easily overlooked. Even the websites of some of the most reputable companies suffer from this problem due to neglect. This is bad for branding and has a negative affect on website usability.
- Effective navigation
Good navigation is one of the most important aspects of website usability. Simple HTML or JavaScript menus tend to work best and appear consistent on all browsers and platforms.
- Contrasting colour schemes
The right contrast between the background of the website and content is one of the most basic yet most important web design principles that should never be overlooked. Good contrast between background and text e.g. black text on a white background makes your content legible and easy to read. Lack of contrast, on the other hand, makes it very difficult for visitors to read your content.
Web applications
- Present
Presentation plays an important role in product marketing and survival. Looks and feel is the first impression for the success and failure of application in this competitive market. The application must be attractive, impressive and according to fashion trend going on in market.
- Hypertext
Hypertext is the base of web application. The basic elements of hypertext are: link, node and anchor. It implements Non linearity, cognitive overload and Disorientation features in application that makes the application highly interactive and improve the performance.
- Content
Content is the informational part. Content generation, integration and updating and availability is an important factor. It contains document, table, text, graphics, and multimedia. It must be of high quality, reliable, consistent and up-to-date. The documents must be properly arranged.
Web services
- XML-Based
Web services use XML at data representation and data transportation layers. Using XML eliminates any networking, operating system, or platform binding. Web services based applications are highly interoperable at their core level.
- Loosely coupled
A consumer of a web service is not tied to that web service directly. The web service interface can change over time without compromising the client's ability to interact with the service. A tightly coupled system implies that the client and server logic are closely tied to one another, implying that if one interface changes, the other must be updated. Adopting a loosely coupled architecture tends to make software systems more manageable and allows simpler integration between different systems.
- Coarse-Grained
Object-oriented technologies such as Java expose their services through individual methods. An individual method is too fine an operation to provide any useful capability at a corporate level. Building a Java program from scratch requires the creation of several fine-grained methods that are then composed into a coarse-grained service that is consumed by either a client or another service.
Businesses and the interfaces that they expose should be coarse-grained. Web services technology provides a natural way of defining coarse-grained services that access the right amount of business logic.
- Ability to be Synchronous or Asynchronous
Synchronicity refers to the binding of the client to the execution of the service. In synchronous invocations, the client blocks and waits for the service to complete its operation before continuing. Asynchronous operations allow a client to invoke a service and then execute other functions.
Asynchronous clients retrieve their result at a later point in time, while synchronous clients receive their result when the service has completed. Asynchronous capability is a key factor in enabling loosely coupled systems.
- Supports Remote Procedure Calls (RPCs)
Web services allow clients to invoke procedures, functions, and methods on remote objects using an XML-based protocol. Remote procedures expose input and output parameters that a web service must support.
Component development through Enterprise JavaBeans (EJBs) and .NET Components has increasingly become a part of architectures and enterprise deployments over the past couple of years. Both technologies are distributed and accessible through a variety of RPC mechanisms.
A web service supports RPC by providing services of its own, equivalent to those of a traditional component, or by translating incoming invocations into an invocation of an EJB or a .NET component.
Rich Internet Applications
- Direct interaction
In a traditional page-based Web application, interaction is limited to a small group of standard controls: checkboxes, radio buttons and form fields. This severely hampers the creation of usable and engaging applications. An RIA can use a wider range of controls that allow greater efficiency and enhance the user experience. In RIAs, for example, users can interact directly with page elements through editing or drag-and-drop tools. They can also do things like pan across a map or other image.
- Partial-page updating
Standard HTML-based Web pages are loaded once. If you update something on a page, the change must be sent back to the server, which makes the changes and then resends the entire page. There's no other way to do it with HTTP and HTML. With traditional Web-based apps, network connectivity issues, processing limitations and other problems require users to wait while the entire page reloads. Even with broadband connections, wait times can be long and disruptive.
But RIAs incorporate additional technologies, such as real-time streaming, high-performance client-side virtual machines, and local caching mechanisms that reduce latency (wait times) and increase responsiveness. A number of commercial development tools (see below) permit this partial-page updating.
- Better feedback
Because of their ability to change parts of pages without reloading, RIAs can provide the user with fast and accurate feedback, real-time confirmation of actions and choices, and informative and detailed error messages.
- Consistency of look and feel
With RIA tools, the user interface and experience with different browsers and operating systems can be more carefully controlled and made consistent.
- Offline use
When connectivity is unavailable, it might still be possible to use an RIA if the app is designed to retain its state locally on the client machine. (Developments in Web standards have also made it possible for some traditional Web applications to do that.)
- Performance impact
Depending on the application and network characteristics, RIAs can often perform better than traditional apps. In particular, applications that avoid round trips to the server by processing locally on the client are likely to be noticeably faster. Offloading such processing to the client machines can also improve server performance. The downside is that small, embedded and mobile devices -- which are increasingly common -- may not have the resources necessary to use such apps.
Different architectures for distributed systems
Client-server architecture
Usually (not always) the client (user) sends a request asking the server for some service and the
server responses with the resources.There can be multiple clients, accessing the same
server. These clients may use different types of devices.
3-tier architecture
This is used, when there is a need for data persistence and also to separate the application logic from the data. This can be seen as an extension of 2-tier architecture.
n-tier architecture
When there is a need for further separation and distribution of the components, more tiers can be
added and extend the 2-tier or 3-tier architecture into an n-tier architecture.
Service Oriented Architecture (SOA)
When different types of distributed systems want to communicate and share their services forming enterprise level systems, the Service Oriented Architecture (SOA) is used.
Compare and contrast the micro-service architecture from monolithic architecture
Monolithic Architecture
When developing a server-side application you can start it with a modular hexagonal or layered architecture which consists of different types of components:
- Presentation — responsible for handling HTTP requests and responding with either HTML or JSON/XML (for web services APIs).
- Business logic — the application’s business logic.
- Database access — data access objects responsible for access the database.
- Application integration — integration with other services (e.g. via messaging or REST API).
Despite having a logically modular architecture, the application is packaged and deployed as a monolith. Benefits of Monolithic Architecture
- Simple to develop.
- Simple to test. For example you can implement end-to-end testing by simply launching the application and testing the UI with Selenium.
- Simple to deploy. You just have to copy the packaged application to a server.
- Simple to scale horizontally by running multiple copies behind a load balancer.
In the early stages of the project it works well and basically most of the big and successful applications which exist today were started as a monolith.
Drawbacks of Monolithic Architecture
- This simple approach has a limitation in size and complexity.
- Application is too large and complex to fully understand and made changes fast and correctly.
- The size of the application can slow down the start-up time.
- You must redeploy the entire application on each update.
- Impact of a change is usually not very well understood which leads to do extensive manual testing.
- Continuous deployment is difficult.
- Monolithic applications can also be difficult to scale when different modules have conflicting resource requirements.
- Another problem with monolithic applications is reliability. Bug in any module (e.g. memory leak) can potentially bring down the entire process. Moreover, since all instances of the application are identical, that bug will impact the availability of the entire application.
- Monolithic applications has a barrier to adopting new technologies. Since changes in frameworks or languages will affect an entire application it is extremely expensive in both time and cost.
Microservices Architecture
The idea is to split your application into a set of smaller, interconnected services instead of building a single monolithic application. Each microservice is a small application that has its own hexagonal architecture consisting of business logic along with various adapters. Some microservices would expose a REST, RPC or message-based API and most services consume APIs provided by other services. Other microservices might implement a web UI.
The Microservice architecture pattern significantly impacts the relationship between the application and the database. Instead of sharing a single database schema with other services, each service has its own database schema. On the one hand, this approach is at odds with the idea of an enterprise-wide data model. Also, it often results in duplication of some data. However, having a database schema per service is essential if you want to benefit from microservices, because it ensures loose coupling. Each of the services has its own database. Moreover, a service can use a type of database that is best suited to its needs, the so-called polyglot persistence architecture.
Some APIs are also exposed to the mobile, desktop, web apps. The apps don’t, however, have direct access to the back-end services. Instead, communication is mediated by an intermediary known as an API Gateway. The API Gateway is responsible for tasks such as load balancing, caching, access control, API metering, and monitoring.
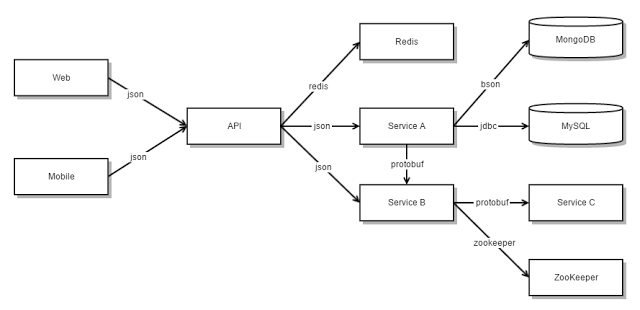
The Microservice architecture pattern corresponds to the Y-axis scaling of the Scale Cube model of scalability.
Benefits of Microservices Architecture
- It tackles the problem of complexity by decomposing application into a set of manageable services which are much faster to develop, and much easier to understand and maintain.
- It enables each service to be developed independently by a team that is focused on that service.
- It reduces barrier of adopting new technologies since the developers are free to choose whatever technologies make sense for their service and not bounded to the choices made at the start of the project.
- Microservice architecture enables each microservice to be deployed independently. As a result, it makes continuous deployment possible for complex applications.
- Microservice architecture enables each service to be scaled independently.
Drawbacks of Microservices Architecture
- Microservices architecture adding a complexity to the project just by the fact that a microservices application is a distributed system. You need to choose and implement an inter-process communication mechanism based on either messaging or RPC and write code to handle partial failure and take into account other fallacies of distributed computing.
- Microservices has the partitioned database architecture. Business transactions that update multiple business entities in a microservices-based application need to update multiple databases owned by different services. Using distributed transactions is usually not an option and you end up having to use an eventual consistency based approach, which is more challenging for developers.
- Testing a microservices application is also much more complex then in case of monolithic web application. For a similar test for a service you would need to launch that service and any services that it depends upon (or at least configure stubs for those services).
- It is more difficult to implement changes that span multiple services. In a monolithic application you could simply change the corresponding modules, integrate the changes, and deploy them in one go. In a Microservice architecture you need to carefully plan and coordinate the rollout of changes to each of the services.
- Deploying a microservices-based application is also more complex. A monolithic application is simply deployed on a set of identical servers behind a load balancer. In contrast, a microservice application typically consists of a large number of services. Each service will have multiple runtime instances. And each instance need to be configured, deployed, scaled, and monitored. In addition, you will also need to implement a service discovery mechanism. Manual approaches to operations cannot scale to this level of complexity and successful deployment a microservices application requires a high level of automation.
MVC style
MVC stands for Model–view–controller. It is a software architectural pattern for implementing user interfaces on computers. It divides a given software application into three interconnected parts, so as to separate internal representations of information from the ways that information is presented to or accepted from the user.
Components of MVC
1) Model: It specifies the logical structure of data in a software application and the high-level class associated with it. It is the domain-specific representation of the data which describes the working of an application. When a model changes its state, domain notifies its associated views, so they can refresh.
2) View: View component is used for all the UI logic of the application and these are the components that display the application’s user interface (UI). It renders the model into a form suitable for interaction. Multiple views can exist for a single model for different purposes.
3) Controller: Controllers act as an interface between Model and View components. It processes all the business logic and incoming requests, manipulate data using the Model component, and interact with the Views to render the final output. It receives input and initiates a response by making calls on model objects.

Advantages of MVC
1) Faster development process: MVC supports rapid and parallel development. With MVC, one programmer can work on the view while other can work on the controller to create business logic of the web application. The application developed using MVC can be three times faster than application developed using other development patterns.
2) Ability to provide multiple views: In the MVC Model, you can create multiple views for a model. Code duplication is very limited in MVC because it separates data and business logic from the display.
3) Support for asynchronous technique: MVC also supports asynchronous technique, which helps developers to develop an application that loads very fast.
4) Modification does not affect the entire model: Modification does not affect the entire model because model part does not depend on the views part. Therefore, any changes in the Model will not affect the entire architecture.
5) MVC model returns the data without formatting: MVC pattern returns data without applying any formatting so the same components can be used and called for use with any interface.
6) SEO friendly Development platform: Using this platform, it is very easy to develop SEO-friendly URLs to generate more visits from a specific application.
Disadvantages of MVC
1) Increased complexity
2) Inefficiency of data access in view
3) Difficulty of using MVC with modern user interface.
4) Need multiple programmers
5) Knowledge on multiple technologies is required.
6) Developer have knowledge of client side code and html code.
Different approaches of use of MVC for web-based systems
CGI::Application
CGI::Application, by Jesse Erlbaum is a relatively simple module that provides a good base-class for a Controller. It’s easy to understand and it has some convenient HTML::Template support (though it doesn’t force you to use HTML::Template if you like another templating system better).
You derive your Controller from the CGI::Application class, handling user requests via the run_modes system and you can use a templating system to implement the Views.
How you implement your Model is entirely up to you. IMO this is a Good Thing; the model is the most specific thing in an application, and a framework should not make unnecessary restrictions on it.
You derive your Controller from the CGI::Application class, handling user requests via the run_modes system and you can use a templating system to implement the Views.
How you implement your Model is entirely up to you. IMO this is a Good Thing; the model is the most specific thing in an application, and a framework should not make unnecessary restrictions on it.
Maypole
Maypole, a fairly new project by Simon Cozens is a complete MVC framework that uses lots of other CPAN modules: CGI::Untaint, Class::DBI and extensions, Template::Toolkit etc. It “aims to be the most generic and extensible [ … ] MVC-based web application framework”, and comes bundled with templates for building CRUD (Create Update Delete) applications. Maypole runs best on mod_perl (mod_perl 2 now supported).
While CGI::Application’s approach is to set up a minimal base for your Controller, giving the programmer as much choice as possible, Maypole’s focus is on rapid development: the example BeerDB application requires about 20 lines of Perl and a database schema. If you’re building a CRUD application on mod_perl, Maypole might be just what you’re looking for.
All this convenience comes at a price, of course - Maypole is big, slow to load (can be a problem in CGI environment), and if you don’t want it to auto-generate a whole CRUD application based on your database schema, it takes a lot more time to figure out than CGI::Application.
While CGI::Application’s approach is to set up a minimal base for your Controller, giving the programmer as much choice as possible, Maypole’s focus is on rapid development: the example BeerDB application requires about 20 lines of Perl and a database schema. If you’re building a CRUD application on mod_perl, Maypole might be just what you’re looking for.
All this convenience comes at a price, of course - Maypole is big, slow to load (can be a problem in CGI environment), and if you don’t want it to auto-generate a whole CRUD application based on your database schema, it takes a lot more time to figure out than CGI::Application.
What’s so useful about it
Separation of requests and pages
Since the Controller is in charge of handling the requests and selecting an appropriate page (View), there is no immediate coupling between the request made by the user and the resulting page.
This turns out to be very useful if the page-flow in the application is complex, but even for simple applications the Controller is a good place to handle common actions - authentication and session management can be handled in the Controller, for instance.
This turns out to be very useful if the page-flow in the application is complex, but even for simple applications the Controller is a good place to handle common actions - authentication and session management can be handled in the Controller, for instance.
Views are dumb
Since all code that does anything except building a nice page for the user is outside the View objects, changing the layout does not involve touching the logic of the application. Since the part of the application that changes the most during and after development is the layout, this means much less chance of adding bugs.
Shielding of the Model implementation
Since all actions on the application state are handled by the Model, it is possible to change the Model’s implementation without touching the user interface, as long as the Model’s public API doesn’t change. (but see L<Coupling between View and Model|Coupling between View and Model>).
Problems and limitations
What goes where
Sometimes is just hard to figure out where a specific piece of the application is supposed to go. Especially dividing the Model from the Controller can be hard. As a rule of thumb, the Controller should be as minimal as possible - it is only responsible for translating HTTP requests into Model actions and selecting the right View - the Model should provide all the behavior it can without handling the HTTP requests or output formatting details.
Coupling between View and Model
One problem with having the View and Controller querying the Model is that changing the Model’s public API means you also have to adapt the Controller and Views that act on it (L<Note 2|Note 2>). Adapting the Controller is usually not too much work, but changing a large number of Views will be annoying.
The Model Model View Controller pattern tries to minimize the impact of these changes by using two Models: a Domain Model and an Application Model - the View only queries the Application Model, and the Application model can query the Domain Model. The Application Model usually partly generated by the GUI design tools. I haven’t used this pattern at all, so I don’t know how useful it is for web applications
The Model Model View Controller pattern tries to minimize the impact of these changes by using two Models: a Domain Model and an Application Model - the View only queries the Application Model, and the Application model can query the Domain Model. The Application Model usually partly generated by the GUI design tools. I haven’t used this pattern at all, so I don’t know how useful it is for web applications
Lots of objects
Creating an MVC application can result in more classes and objects than a “page-based” system. That means more design up front. On the other hand, a well designed MVC system will be easier to adapt and expand, because the code will be separated better.
Need for very specific type of communication technologies in distributed systems
Communication in Distributed Software Development is an area of study that considers communication processes and their effects when applied to software development in a globally distributed development process. The importance of communication and coordination in software development is widely studied [1] and organizational communication studies these implications at an organizational level. This also applies to a setting where teams and team members work in separate physical locations. The imposed distance introduces new challenges in communication, which is no longer a face to face process, and may also be subjected to other constraints such as teams in opposing time zones with a small overlap in working hours.
There are several reasons that force elements from the same project to work in geographically separated areas, ranging from different teams in the same company to outsourcing and offshoring, to which different constraints and necessities in communication apply. The added communication challenges result in the adoption of a wide range of different communication methods usually used in combination. They can either be in real time as in the case of a video conference, or in an asynchronous way such as email. While a video conference might allow the developers to be more efficient with regards to their time spent communicating, it is more difficult to accomplish when teams work in different time zones, in which case using an email or a messaging service might be more useful.
Compare and contrast RPC with RMI

RPC and RMI are the mechanisms which enable a client to invoke the procedure or method from the server through establishing communication between client and server. The common difference between RPC and RMI is that RPC only supports procedural programming whereas RMI supports object-oriented programming. Another major difference between the two is that the parameters passed to remote procedures call consist of ordinary data structures. On the other hand, the parameters passed to remote method consist of objects.
Comparison Chart
| BASIS FOR COMPARISON | RPC | RMI |
|---|---|---|
| Supports | Procedural programming | Object-oriented programming |
| Parameters | Ordinary data structures are passed to remote procedures. | Objects are passed to remote methods. |
| Efficiency | Lower than RMI | More than RPC and supported by modern programming approach (i.e. Object-oriented paradigms) |
| Overheads | More | Less comparatively |
| In-out parameters are mandatory. | Yes | Not necessarily |
| Provision of ease of programming | High | low |
Definition of RPC
Remote Procedure Call (RPC) is a programming language feature devised for the distributed computing and based on semantics of local procedure calls. It is the most common forms of remote service and was designed as a way to abstract the procedure call mechanism to use between systems connected through a network. It is similar to IPC mechanism where the operating system allows the processes to manage shared data and deal with an environment where different processes are executing on separate systems and necessarily require message-based communication.
Definition of RMI
Remote Method Invocation (RMI) is similar to RPC but is language specific and a feature of java. A thread is permitted to call the method on a remote object. To maintain the transparency on the client and server side, it implements remote object using stubs and skeletons. The stub resides with the client and for the remote object it behaves as a proxy.
Key Differences Between RPC and RMI
- RPC supports procedural programming paradigms thus is C based, while RMI supports object-oriented programming paradigms and is java based.
- The parameters passed to remote procedures in RPC are the ordinary data structures. On the contrary, RMI transits objects as a parameter to the remote method.
- RPC can be considered as the older version of RMI, and it is used in the programming languages that support procedural programming, and it can only use pass by value method. As against, RMI facility is devised based on modern programming approach, which could use pass by value or reference. Another advantage of RMI is that the parameters passed by reference can be changed.
- RPC protocol generates more overheads than RMI.
- The parameters passed in RPC must be “in-out” which means that the value passed to the procedure and the output value must have the same datatypes. In contrast, there is no compulsion of passing “in-out” parameters in RMI.
- In RPC, references could not be probable because the two processes have the distinct address space, but it is possible in case of RMI.
Need for CORBA
CORBA is a specification for creating distributed object-based applications. The CORBA architecture and specification were developed by the Object Management Group (OMG). The OMG is a consortium of several hundred information systems vendors. The goal of CORBA is to promote an object-oriented approach to building and integrating distributed software applications.
The CORBA specification provides a broad and consistent model for building distributed applications by defining:
•
|
An object model for building distributed applications.
|
•
|
A common set of application programming objects to be used by the client and server applications.
|
•
|
A syntax for describing the interfaces of objects used in the development of distributed applications.
|
•
|
Support for use by applications written in multiple programming languages.
|
The CORBA specification describes how to develop an implementation of CORBA. It also describes programming language bindings that developers use to develop applications.
To illustrate the advantages of using the CORBA architecture, this section compares early client/server application development techniques to CORBA development techniques.
The CORBA model provides a more flexible approach to developing distributed applications. The CORBA model:
•
|
Formally separates the client and server portions of the application
|
A CORBA client application knows only how to ask for something to be done, and a CORBA server application knows only how to accomplish a task that a client application has requested it to do. Because of this separation, developers can change the way a server accomplishes a task without affecting how the client application asks for the server application to accomplish the task.
•
|
Logically separates an application into objects that can perform certain tasks, called operations
|
CORBA is based on the distributed object computing model, which combines the concepts of distributed computing (client and server) and object-oriented computing (based on objects and operations).
In object-oriented computing, objects are the entities that make up the application, and operations are the tasks that a server can perform on those objects. For example, a banking application could have objects for customer accounts, and operations for depositing, withdrawing, and viewing the balance in the accounts.
•
|
Provides data marshaling to send and receive data with remote or local machine applications
|
For example, the CORBA model automatically formats for big or little endian as needed. (Refer to the preceding section for a description of data marshaling.)
•
|
Hides network protocol interfaces from the applications
|
The CORBA model handles all network interfaces. The applications see only objects. The applications can run on different machines and, because all the network interface code is handled by the ORB, the application does not require any network-related changes if it is later deployed on a machine that supports a different network protocol.
The CORBA model allows client applications to make requests to server applications, and to receive responses from them without direct knowledge of the information source or its location. In a CORBA environment, applications do not need to include network and operating system information to communicate; instead, client and server applications communicate with the Object Request Broker (ORB). The following figure shows the ORB in a client/server environment.
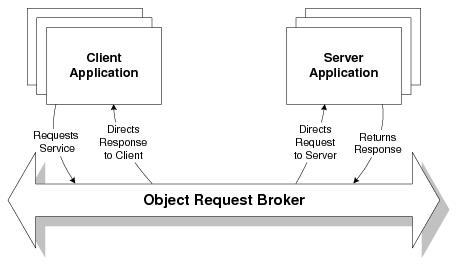
CORBA defines the ORB as an intermediary between client and server applications. The ORB delivers client requests to the appropriate server applications and returns the server responses to the requesting client application. Using an ORB, a client application can request a service without knowing the location of the server application or how the server application will fulfill the request.
In the CORBA model, client applications need to know only what requests they can make and how to make the requests; they do not need to be coded with any implementation details of the server or of the data formats. Server applications need only know how to fulfill the requests, not how to return data to the client application.
This means that programmers can change the way a server application accomplishes a task without affecting how the client application asks for the server application to accomplish that task. For example, as long as the interfaces between the client and the server applications do not change, programmers can evolve and create new implementations of a server application without changing the client application; in addition, they can create new client applications without changing the server applications.
XML Specifications
- Character
- An XML document is a string of characters. Almost every legal Unicode character may appear in an XML document.
- Processor and application
- The processor analyzes the markup and passes structured information to an application. The specification places requirements on what an XML processor must do and not do, but the application is outside its scope. The processor (as the specification calls it) is often referred to colloquially as an XML parser.
- Markup and content
- The characters making up an XML document are divided into markup and content, which may be distinguished by the application of simple syntactic rules. Generally, strings that constitute markup either begin with the character
<and end with a>, or they begin with the character&and end with a;. Strings of characters that are not markup are content. However, in a CDATA section, the delimiters<![CDATA[and]]>are classified as markup, while the text between them is classified as content. In addition, whitespace before and after the outermost element is classified as markup.
- Tag
- A tag is a markup construct that begins with
<and ends with>. Tags come in three flavors:- start-tag, such as
<section>; - end-tag, such as
</section>; - empty-element tag, such as
<line-break />.
- start-tag, such as
- Element
- An element is a logical document component that either begins with a start-tag and ends with a matching end-tag or consists only of an empty-element tag. The characters between the start-tag and end-tag, if any, are the element's content, and may contain markup, including other elements, which are called child elements. An example is
<greeting>Hello, world!</greeting>. Another is<line-break />.
- Attribute
- An attribute is a markup construct consisting of a name–value pair that exists within a start-tag or empty-element tag. An example is
<img src="madonna.jpg" alt="Madonna" />, where the names of the attributes are "src" and "alt", and their values are "madonna.jpg" and "Madonna" respectively. Another example is<step number="3">Connect A to B.</step>, where the name of the attribute is "number" and its value is "3". An XML attribute can only have a single value and each attribute can appear at most once on each element. In the common situation where a list of multiple values is desired, this must be done by encoding the list into a well-formed XML attribute[i] with some format beyond what XML defines itself. Usually this is either a comma or semi-colon delimited list or, if the individual values are known not to contain spaces,[ii] a space-delimited list can be used.<div class="inner greeting-box">Welcome!</div>, where the attribute "class" has both the value "inner greeting-box" and also indicates the two CSS class names "inner" and "greeting-box".
- XML declaration
- XML documents may begin with an XML declaration that describes some information about themselves. An example is
<?xml version="1.0" encoding="UTF-8"?>.
Characters and escaping[edit]
XML documents consist entirely of characters from the Unicode repertoire. Except for a small number of specifically excluded control characters, any character defined by Unicode may appear within the content of an XML document.
XML includes facilities for identifying the encoding of the Unicode characters that make up the document, and for expressing characters that, for one reason or another, cannot be used directly.
Valid characters[edit]
Unicode code points in the following ranges are valid in XML 1.0 documents:[9]
- U+0009 (Horizontal Tab), U+000A (Line Feed), U+000D (Carriage Return): these are the only C0 controls accepted in XML 1.0;
- U+0020–U+D7FF, U+E000–U+FFFD: this excludes some (not all) non-characters in the BMP (all surrogates, U+FFFE and U+FFFF are forbidden);
- U+10000–U+10FFFF: this includes all code points in supplementary planes, including non-characters.
XML 1.1[10] extends the set of allowed characters to include all the above, plus the remaining characters in the range U+0001–U+001F. At the same time, however, it restricts the use of C0 and C1 control characters other than U+0009 (Horizontal Tab), U+000A (Line Feed), U+000D (Carriage Return), and U+0085 (Next Line) by requiring them to be written in escaped form (for example U+0001 must be written as
 or its equivalent). In the case of C1 characters, this restriction is a backwards incompatibility; it was introduced to allow common encoding errors to be detected.
The code point U+0000 (Null) is the only character that is not permitted in any XML 1.0 or 1.1 document.
Encoding detection[edit]
The Unicode character set can be encoded into bytes for storage or transmission in a variety of different ways, called "encodings". Unicode itself defines encodings that cover the entire repertoire; well-known ones include UTF-8and UTF-16.[11] There are many other text encodings that predate Unicode, such as ASCII and ISO/IEC 8859; their character repertoires in almost every case are subsets of the Unicode character set.
XML allows the use of any of the Unicode-defined encodings, and any other encodings whose characters also appear in Unicode. XML also provides a mechanism whereby an XML processor can reliably, without any prior knowledge, determine which encoding is being used.[12] Encodings other than UTF-8 and UTF-16 are not necessarily recognized by every XML parser.
Escaping[edit]
XML provides escape facilities for including characters that are problematic to include directly. For example:
- The characters "<" and "&" are key syntax markers and may never appear in content outside a CDATA section. It is allowed, but not recommended, to use "<" in XML entity values.[13]
- Some character encodings support only a subset of Unicode. For example, it is legal to encode an XML document in ASCII, but ASCII lacks code points for Unicode characters such as "é".
- It might not be possible to type the character on the author's machine.
- Some characters have glyphs that cannot be visually distinguished from other characters, such as the non-breaking space (
 ) " " and the space ( ) " ", and the Cyrillic capital letter A (А) "А" and the Latin capital letter A (A) "A".
There are five predefined entities:
<represents "<";>represents ">";&represents "&";'represents "'";"represents '"'.
All permitted Unicode characters may be represented with a numeric character reference. Consider the Chinese character "中", whose numeric code in Unicode is hexadecimal 4E2D, or decimal 20,013. A user whose keyboard offers no method for entering this character could still insert it in an XML document encoded either as
中 or 中. Similarly, the string "I <3 Jörg" could be encoded for inclusion in an XML document as I <3 Jörg.� is not permitted, however, because the null character is one of the control characters excluded from XML, even when using a numeric character reference.[14] An alternative encoding mechanism such as Base64 is needed to represent such characters.Comments[edit]
Comments may appear anywhere in a document outside other markup. Comments cannot appear before the XML declaration. Comments begin with
<!-- and end with -->. For compatibility with SGML, the string "--" (double-hyphen) is not allowed inside comments;[15] this means comments cannot be nested. The ampersand has no special significance within comments, so entity and character references are not recognized as such, and there is no way to represent characters outside the character set of the document encoding.
An example of a valid comment:
<!--no need to escape <code> & such in comments-->International use[edit]
XML 1.0 (Fifth Edition) and XML 1.1 support the direct use of almost any Unicode character in element names, attributes, comments, character data, and processing instructions (other than the ones that have special symbolic meaning in XML itself, such as the less-than sign, "<"). The following is a well-formed XML document including Chinese, Armenian and Cyrillic characters:
<?xml version="1.0" encoding="UTF-8"?>
<俄语 լեզու="ռուսերեն">данные</俄语>
Well-formedness and error-handling[edit]
The XML specification defines an XML document as a well-formed text, meaning that it satisfies a list of syntax rules provided in the specification. Some key points in the fairly lengthy list include:
- The document contains only properly encoded legal Unicode characters.
- None of the special syntax characters such as
<and&appear except when performing their markup-delineation roles. - The start-tag, end-tag, and empty-element tag that delimit elements are correctly nested, with none missing and none overlapping.
- Tag names are case-sensitive; the start-tag and end-tag must match exactly.
- Tag names cannot contain any of the characters !"#$%&'()*+,/;<=>?@[\]^`{|}~, nor a space character, and cannot begin with "-", ".", or a numeric digit.
- A single root element contains all the other elements.
The definition of an XML document excludes texts that contain violations of well-formedness rules; they are simply not XML. An XML processor that encounters such a violation is required to report such errors and to cease normal processing. This policy, occasionally referred to as "draconian error handling," stands in notable contrast to the behavior of programs that process HTML, which are designed to produce a reasonable result even in the presence of severe markup errors.[16] XML's policy in this area has been criticized as a violation of Postel's law ("Be conservative in what you send; be liberal in what you accept").[17]
The XML specification defines a valid XML document as a well-formed XML document which also conforms to the rules of a Document Type Definition (DTD).[18][19]
Schemas and validation[edit]
In addition to being well-formed, an XML document may be valid. This means that it contains a reference to a Document Type Definition (DTD), and that its elements and attributes are declared in that DTD and follow the grammatical rules for them that the DTD specifies.
XML processors are classified as validating or non-validating depending on whether or not they check XML documents for validity. A processor that discovers a validity error must be able to report it, but may continue normal processing.
A DTD is an example of a schema or grammar. Since the initial publication of XML 1.0, there has been substantial work in the area of schema languages for XML. Such schema languages typically constrain the set of elements that may be used in a document, which attributes may be applied to them, the order in which they may appear, and the allowable parent/child relationships.
Document Type Definition[edit]
The oldest schema language for XML is the Document Type Definition (DTD), inherited from SGML.
DTDs have the following benefits:
- DTD support is ubiquitous due to its inclusion in the XML 1.0 standard.
- DTDs are terse compared to element-based schema languages and consequently present more information in a single screen.
- DTDs allow the declaration of standard public entity sets for publishing characters.
- DTDs define a document type rather than the types used by a namespace, thus grouping all constraints for a document in a single collection.
DTDs have the following limitations:
- They have no explicit support for newer features of XML, most importantly namespaces.
- They lack expressiveness. XML DTDs are simpler than SGML DTDs and there are certain structures that cannot be expressed with regular grammars. DTDs only support rudimentary datatypes.
- They lack readability. DTD designers typically make heavy use of parameter entities (which behave essentially as textual macros), which make it easier to define complex grammars, but at the expense of clarity.
- They use a syntax based on regular expression syntax, inherited from SGML, to describe the schema. Typical XML APIs such as SAX do not attempt to offer applications a structured representation of the syntax, so it is less accessible to programmers than an element-based syntax may be.
Two peculiar features that distinguish DTDs from other schema types are the syntactic support for embedding a DTD within XML documents and for defining entities, which are arbitrary fragments of text and/or markup that the XML processor inserts in the DTD itself and in the XML document wherever they are referenced, like character escapes.
DTD technology is still used in many applications because of its ubiquity.
XML Schema[edit]
A newer schema language, described by the W3C as the successor of DTDs, is XML Schema, often referred to by the initialism for XML Schema instances, XSD (XML Schema Definition). XSDs are far more powerful than DTDs in describing XML languages. They use a rich datatyping system and allow for more detailed constraints on an XML document's logical structure. XSDs also use an XML-based format, which makes it possible to use ordinary XML tools to help process them.
xs:schema element that defines a schema:
<?xml version="1.0" encoding="ISO-8859-1" ?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"></xs:schema>
RELAX NG[edit]
RELAX NG (Regular Language for XML Next Generation) was initially specified by OASIS and is now a standard (Part 2: Regular-grammar-based validation of ISO/IEC 19757 - DSDL). RELAX NG schemas may be written in either an XML based syntax or a more compact non-XML syntax; the two syntaxes are isomorphic and James Clark's conversion tool—Trang—can convert between them without loss of information. RELAX NG has a simpler definition and validation framework than XML Schema, making it easier to use and implement. It also has the ability to use datatype framework plug-ins; a RELAX NG schema author, for example, can require values in an XML document to conform to definitions in XML Schema Datatypes.
Schematron[edit]
Schematron is a language for making assertions about the presence or absence of patterns in an XML document. It typically uses XPath expressions. Schematron is now a standard (Part 3: Rule-based validation of ISO/IEC 19757 - DSDL).
DSDL and other schema languages[edit]
DSDL (Document Schema Definition Languages) is a multi-part ISO/IEC standard (ISO/IEC 19757) that brings together a comprehensive set of small schema languages, each targeted at specific problems. DSDL includes RELAX NG full and compact syntax, Schematron assertion language, and languages for defining datatypes, character repertoire constraints, renaming and entity expansion, and namespace-based routing of document fragments to different validators. DSDL schema languages do not have the vendor support of XML Schemas yet, and are to some extent a grassroots reaction of industrial publishers to the lack of utility of XML Schemas for publishing.
Some schema languages not only describe the structure of a particular XML format but also offer limited facilities to influence processing of individual XML files that conform to this format. DTDs and XSDs both have this ability; they can for instance provide the infoset augmentation facility and attribute defaults. RELAX NG and Schematron intentionally do not provide these.
Related specifications[edit]
A cluster of specifications closely related to XML have been developed, starting soon after the initial publication of XML 1.0. It is frequently the case that the term "XML" is used to refer to XML together with one or more of these other technologies that have come to be seen as part of the XML core.
- XML namespaces enable the same document to contain XML elements and attributes taken from different vocabularies, without any naming collisions occurring. Although XML Namespaces are not part of the XML specification itself, virtually all XML software also supports XML Namespaces.
- XML Base defines the
xml:baseattribute, which may be used to set the base for resolution of relative URI references within the scope of a single XML element. - XML Information Set or XML Infoset is an abstract data model for XML documents in terms of information items. The infoset is commonly used in the specifications of XML languages, for convenience in describing constraints on the XML constructs those languages allow.
- XSL (Extensible Stylesheet Language) is a family of languages used to transform and render XML documents, split into three parts:
- XSLT (XSL Transformations), an XML language for transforming XML documents into other XML documents or other formats such as HTML, plain text, or XSL-FO. XSLT is very tightly coupled with XPath, which it uses to address components of the input XML document, mainly elements and attributes.
- XSL-FO (XSL Formatting Objects), an XML language for rendering XML documents, often used to generate PDFs.
- XPath (XML Path Language), a non-XML language for addressing the components (elements, attributes, and so on) of an XML document. XPath is widely used in other core-XML specifications and in programming libraries for accessing XML-encoded data.
- XQuery (XML Query) is an XML query language strongly rooted in XPath and XML Schema. It provides methods to access, manipulate and return XML, and is mainly conceived as a query language for XML databases.
- XML Signature defines syntax and processing rules for creating digital signatures on XML content.
- XML Encryption defines syntax and processing rules for encrypting XML content.
- xml-model (Part 11: Schema Association of ISO/IEC 19757 - DSDL) defines a means of associating any xml document with any of the schema types mentioned above.
JSON vs XML
Both JSON and XML can be used to receive data from a web server.
The following JSON and XML examples both define an employees object, with an array of 3 employees:
JSON Example
{"employees":[
{ "firstName":"John", "lastName":"Doe" },
{ "firstName":"Anna", "lastName":"Smith" },
{ "firstName":"Peter", "lastName":"Jones" }
]}
XML Example
<employees>
<employee>
<firstName>John</firstName> <lastName>Doe</lastName>
</employee>
<employee>
<firstName>Anna</firstName> <lastName>Smith</lastName>
</employee>
<employee>
<firstName>Peter</firstName> <lastName>Jones</lastName>
</employee>
</employees>
JSON is Like XML Because
- Both JSON and XML are "self describing" (human readable)
- Both JSON and XML are hierarchical (values within values)
- Both JSON and XML can be parsed and used by lots of programming languages
- Both JSON and XML can be fetched with an XMLHttpRequest
JSON is Unlike XML Because
- JSON doesn't use end tag
- JSON is shorter
- JSON is quicker to read and write
- JSON can use arrays
The biggest difference is:
XML has to be parsed with an XML parser. JSON can be parsed by a standard JavaScript function.
Why JSON is Better Than XML
XML is much more difficult to parse than JSON.
JSON is parsed into a ready-to-use JavaScript object.
JSON is parsed into a ready-to-use JavaScript object.
For AJAX applications, JSON is faster and easier than XML:
Using XML
- Fetch an XML document
- Use the XML DOM to loop through the document
- Extract values and store in variables
Using JSON
- Fetch a JSON string
- JSON.Parse the JSON string
Other data formatting/structuring techniques available for the communication of web-based systems
•Plain text
• Files (text, image)
•Query string



No comments:
Post a Comment